Release 8.1.5
A67775-01
Library |
Product |
Contents |
Index |
| Oracle8i Tuning Release 8.1.5 A67775-01 |
|
![]()
![]()
This chapter provides a conceptual explanation of parallel execution performance issues and additional performance enhancement techniques. It also summarizes tools and techniques you can use to obtain performance feedback on parallel operations and explains how to resolve performance problems.
Oracle8i Concepts, for basic principles of parallel execution. Also see your operating system-specific Oracle documentation for more information about tuning while using parallel execution. See your operating system-specific Oracle documentation for more information about tuning while using parallel execution.
See Also:
A key to the tuning of parallel operations is an understanding of the relationship between memory requirements, the number of users (processes) a system can support, and the maximum number of parallel execution servers. The goal is to obtain dramatic performance enhancements made possible by parallelizing certain operations, and by using hash joins rather than sort merge joins. You must balance this performance goal with the need to support multiple users.
In considering the maximum number of processes a system can support, it is useful to divide the processes into three classes, based on their memory requirements. Table 27-1 defines high, medium, and low memory processes.
Analyze the maximum number of processes that can fit in memory as follows:
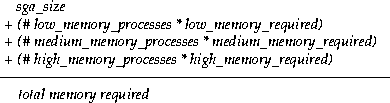
| Class | Description |
|---|---|
|
100KB to 1MB |
Low Memory Processes include table scans, index lookups, index nested loop joins; single-row aggregates (such as sum or average with no GROUP BYs, or very few groups), and sorts that return only a few rows; and direct loading. This class of Data Warehousing process is similar to OLTP processes in the amount of memory required. Process memory could be as low as a few hundred kilobytes of fixed overhead. You could potentially support thousands of users performing this kind of operation. You can take this requirement even lower by using the multi-threaded server, and support even more users. |
|
1MB to 10MB |
Medium Memory Processes include large sorts, sort merge join, GROUP BY or ORDER BY operations returning a large number of rows, parallel insert operations that involve index maintenance, and index creation. These processes require the fixed overhead needed by a low memory process, plus one or more sort areas, depending on the operation. For example, a typical sort merge join would sort both its inputs--resulting in two sort areas. GROUP BY or ORDER BY operations with many groups or rows also require sort areas. Look at the EXPLAIN PLAN output for the operation to identify the number and type of joins, and the number and type of sorts. Optimizer statistics in the plan show the size of the operations. When planning joins, remember that you have several choices. The EXPLAIN PLAN statement is described in Chapter 13, "Using EXPLAIN PLAN". |
|
10MB to 100MB |
High memory processes include one or more hash joins, or a combination of one or more hash joins with large sorts. These processes require the fixed overhead needed by a low memory process, plus hash area. The hash area size required might range from 8MB to 32MB, and you might need two of them. If you are performing 2 or more serial hash joins, each process uses 2 hash areas. In a parallel operation, each parallel execution server does at most 1 hash join at a time; therefore, you would need 1 hash area size per server. In summary, the amount of hash join memory for an operation equals the DOP multiplied by hash area size, multiplied by the lesser of either 2 or the number of hash joins in the operation. |
The formula to calculate the maximum number of processes your system can support (referred to here as max_processes) is:
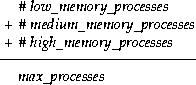
In general, if the value for max_processes is much larger than the number of users, consider using parallel operations. If max_processes is considerably less than the number of users, consider other alternatives, such as those described in "Balancing the Formula".
With the exception of parallel update and delete, parallel operations do not generally benefit from larger buffer pool sizes. Parallel update and delete benefit from a larger buffer pool when they update indexes. This is because index updates have a random access pattern and I/O activity can be reduced if an entire index or its interior nodes can be kept in the buffer pool. Other parallel operations can benefit only if you can increase the size of the buffer pool and thereby accommodate the inner table or index for a nested loop join.
Use the following techniques to balance the memory/users/server formula given in Figure 27-1:
You can permit the potential workload to exceed the limits recommended in the formula. Total memory required, minus the SGA size, can be multiplied by a factor of 1.2, to allow for 20% oversubscription. Thus, if you have 1GB of memory, you might be able to support 1.2GB of demand: the other 20% could be handled by the paging system.
You must, however, verify that a particular degree of oversubscription is viable on your system. Do this by monitoring the paging rate and making sure you are not spending more than a very small percent of the time waiting for the paging subsystem. Your system may perform acceptably even if oversubscribed by 60%, if on average not all of the processes are performing hash joins concurrently. Users might then try to use more than the available memory, so you must continually monitor paging activity in such a situation. If paging dramatically increases, consider other alternatives.
On average, no more than 5% of the time should be spent simply waiting in the operating system on page faults. More than 5% wait time indicates your paging subsystem is I/O bound. Use your operating system monitor to check wait time: The sum of time waiting and time running equals 100%. If your total system load is close to 100% of your CPU, your system is not spending a lot of time waiting. If you are waiting, it is not be due to paging.
If wait time for paging devices exceeds 5%, you must most likely reduce memory requirements in one of these ways:
If the wait time indicates an I/O bottleneck in the paging subsystem, you could resolve this by striping.
This section describes two things you can do to reduce the number of memory-intensive processes:
You can adjust not only the number of operations that run in parallel, but also the DOP (degree of parallelism) with which operations run. To do this, issue an ALTER TABLE statement with a PARALLEL clause, or use a hint.
|
See Also:
For more information on parallel execution, refer to Chapter 26, "Tuning Parallel Execution". For more information about the ALTER TABLE statement, refer to the Oracle8i SQL Reference. |
You can limit the parallel pool by reducing the value of PARALLEL_MAX_SERVERS. Doing so places a system-level limit on the total amount of parallelism. It also makes your system easier to administer. More processes are then forced to run in serial mode.
If you enable the parallel adaptive multi-user feature by setting the PARALLEL_ADATIVE_MULTI_USER parameter to TRUE, Oracle controls adjusts DOP based on user load.
|
See Also:
For more information on the parallel adaptive multi-user feature, please refer to "Degree of Parallelism and Adaptive Multi-User and How They Interact". |
Queueing jobs is another way to reduce the number of processes but not reduce parallelism. Rather than reducing parallelism for all operations, you may be able to schedule large parallel batch jobs to run with full parallelism one at a time, rather than concurrently. Queries at the head of the queue would have a fast response time, those at the end of the queue would have a slow response time. However, this method entails a certain amount of administrative overhead.
The following discussion focuses upon the relationship of HASH_AREA_SIZE to memory, but all the same considerations apply to SORT_AREA_SIZE. The lower bound of SORT_AREA_SIZE, however, is not as critical as the 8MB recommended minimum HASH_AREA_SIZE.
If every operation performs a hash join and a sort, the high memory requirement limits the number of processes you can have. To allow more users to run concurrently you may need to reduce the data warehouse's process memory.
You can move a process from the high-memory to the medium-memory class by reducing the value for HASH_AREA_SIZE. With the same amount of memory, Oracle always processes hash joins faster than sort merge joins. Therefore, Oracle does not recommend that you make your hash area smaller than your sort area.
If you need to support thousands of users, create access paths so operations do not access data unnecessarily. To do this, perform one or more of the following:
For more information about summary tables, please refer to Section VI, "Materialized Views".
See Also:
The easiest way to decrease parallelism for multiple users is to enable the parallel adaptive multi-user feature as described under the heading "Degree of Parallelism and Adaptive Multi-User and How They Interact".
If you decide to control this manually, however, there is a trade-off between parallelism for fast single-user response time and efficient use of resources for multiple users. For example, a system with 2GB of memory and a HASH_AREA_SIZE of 32MB can support about 60 parallel execution servers. A 10 CPU machine can support up to 3 concurrent parallel operations (2 * 10 * 3 = 60). To support 12 concurrent parallel operations, you could override the default parallelism (reduce it), decrease HASH_AREA_SIZE, buy more memory, or you could use some combination of these three strategies. Thus you could ALTER TABLE t PARALLEL (DOP = 5) for all parallel tables t, set HASH_AREA_SIZE to 16MB, and increase PARALLEL_MAX_SERVERS to 120. By reducing the memory of each parallel server by a factor of 2, and reducing the parallelism of a single operation by a factor of 2, the system can accommodate 2 * 2 = 4 times more concurrent parallel operations.
The penalty for using such an approach is that when a single operation happens to be running, the system uses just half the CPU resource of the 10 CPU machine. The other half is idle until another operation is started.
To determine whether your system is being fully utilized, use one of the graphical system monitors available on most operating systems. These monitors often give you a better idea of CPU utilization and system performance than monitoring the execution time of an operation. Consult your operating system documentation to determine whether your system supports graphical system monitors.
The examples in this section show how to evaluate the relationship between memory, users, and parallel execution servers, and balance the formula given in Figure 27-1. They show concretely how you might adjust your system workload to accommodate the necessary number of processes and users.
Assume your system has 1GB of memory, the DOP is 10, and that your users perform 2 hash joins with 3 or more tables. If you need 300MB for the SGA, that leaves 700MB to accommodate processes. If you allow a generous hash area size, such as 32MB, then your system can support:
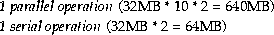
This makes a total of 704MB. In this case, the memory is not significantly oversubscribed.
Remember that every parallel, hash, or sort merge join operation takes a number of parallel execution servers equal to twice the DOP, utilizing 2 server sets, and often each individual process of a parallel operation uses a significant amount of memory. Thus you can support many more users by running their processes serially, or by using less parallelism to run their processes.
To service more users, you can reduce hash area size to 2MB. This configuration can support 17 parallel operations, or 170 serial operations, but response times may be significantly higher than if you were using hash joins.
The trade-off in this example reveals that by reducing memory per process by a factor of 16, you can increase the number of concurrent users by a factor of 16. Thus the amount of physical memory on the machine imposes another limit on the total number of parallel operations you can run involving hash joins and sorts.
In a mixed workload example, consider a user population with diverse needs, as described in Table 27-2. In this situation, you would have to selectively allocate resources. You could not allow everyone to run hash joins--even though they outperform sort merge joins--because you do not have adequate memory to support workload level.
You might consider it safe to oversubscribe by 50%, because of the infrequent batch jobs that run during the day: 700MB * 1.5 = 1.05GB. This gives you enough virtual memory for the total workload.
Suppose your system has 2GB of memory and you have 200 query server processes and 100 users doing performing heavy data warehousing operations involving hash joins. You decide not to consider tasks such as index retrievals and small sorts. Instead, you concentrate on the high memory processes. You might have 300 processes, of which 200 must come from the parallel pool and 100 are single threaded. One quarter of the total 2GB of memory might be used by the SGA, leaving 1.5GB of memory to handle all the processes. You could apply the formula considering only the high memory requirements, including a factor of 20% oversubscription:
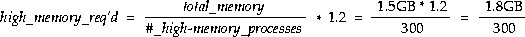
Here, 5MB = 1.8GB/300. Less than 5MB of hash area would be available for each process, whereas 8MB is the recommended minimum. If you must have 300 processes, you may need to reduce hash area size to change them from the highly memory-intensive class to the moderately memory-intensive class. Then they may fit within your system's constraints.
Consider a system with 2GB of memory and 10 users who want to run intensive data warehousing parallel operations concurrently and still have good performance. If you choose a DOP of 10, then the 10 users will require 200 processes. (Processes running large joins need twice the number of parallel execution servers as the DOP, so you would set PARALLEL_MAX_SERVERS to 10 * 10 * 2.) In this example each process would get 1.8GB/200--or about 9MB of hash area--which should be adequate.
With only 5 users doing large hash joins, each process would get over 16MB of hash area, which would be fine. But if you want 32MB available for lots of hash joins, the system could only support 2 or 3 users. By contrast, if users are just computing aggregates the system needs adequate sort area size--and can have many more users.
If a system with 2GB of memory needs to support 1000 users, all of them running large queries, you must evaluate the situation carefully. Here, the per-user memory budget is only 1.8MB (that is, 1.8GB divided by 1,000). Since this figure is at the low end of the medium memory process class, you must rule out parallel operations, which use even more resources. You must also rule out large hash joins. Each sequential process could require up to 2 hash areas plus the sort area, so you would have to set HASH_AREA_SIZE to the same value as SORT_AREA_SIZE, which would be 600KB(1.8MB/3). Such a small hash area size is likely to be ineffective.
Given the organization's resources and business needs, is it reasonable for you to upgrade your system's memory? If memory upgrade is not an option, then you must change your expectations. To adjust the balance you might:
This section describes space management issues that occur when using parallel execution. These issues are:
These problems become particularly important for parallel operations in an OPS (Oracle Parallel Server) environment; the more nodes that are involved, the more tuning becomes critical.
If you can implement locally-managed tablespaces, you can avoid these issues altogether.
|
Note: For more information about locally-managed tablespaces, please refer to the Oracle8i Administrator's Guide. |
Every space management transaction in the database (such as creation of temporary segments in PARALLEL CREATE TABLE, or parallel direct-load inserts of non-partitioned tables) is controlled by a single ST enqueue. A high transaction rate, for example, more than 2 or 3 transactions per minute, on ST enqueues may result in poor scalability on OPS with many nodes, or a timeout waiting for space management resources. Use the V$ROWCACHE and V$LIBRARYCACHE views to locate this type of contention.
Try to minimize the number of space management transactions, in particular:
Use dedicated temporary tablespaces to optimize space management for sorts. This is particularly beneficial on OPS. You can monitor this using V$SORT_SEGMENT.
Set INITIAL and NEXT extent size to a value in the range of 1MB to 10MB. Processes may use temporary space at a rate of up to 1MB per second. Do not accept the default value of 40KB for next extent size, because this will result in many requests for space per second.
External fragmentation is a concern for parallel load, direct-load insert, and PARALLEL CREATE TABLE ... AS SELECT. Memory tends to become fragmented as extents are allocated and data is inserted and deleted. This may result in a fair amount of free space that is unusable because it consists of small, non-contiguous chunks of memory.
To reduce external fragmentation on partitioned tables, set all extents to the same size. Set the value for NEXT equal to the value for INITIAL and set PERCENT_INCREASE to zero. The system can handle this well with a few thousand extents per object. Therefore, set MAXEXTENTS to, for example, 1,000 to 3,000; never attempt to use a value for MAXEXTENS in excess of 10,000. For tables that are not partitioned, the initial extent should be small.
This section describe several aspects of parallel execution for OPS.
This section provides parallel execution tuning guidelines for optimal lock management on OPS.
To optimize parallel execution on OPS, you need to correctly set GC_FILES_TO_LOCKS. On OPS, a certain number of parallel cache management (PCM) locks are assigned to each data file. Data block address (DBA) locking in its default behavior assigns one lock to each block. During a full table scan a PCM lock must then be acquired for each block read into the scan. To speed up full table scans, you have three possibilities:
To speed up parallel DML operations, consider using hashed locking or a high grouping factor rather than database address locking. A parallel execution server works on non-overlapping partitions; it is recommended that partitions not share files. You can thus reduce the number of lock operations by having only 1 hashed lock per file. Because the parallel execution server only works on non-overlapping files, there are no lock pings.
The following guidelines effect memory usage, and thus indirectly affect performance:
For example, on a read-only database with a data warehousing application's query-only workload, you might create 500 PCM locks on the SYSTEM tablespace in file 1, then create 50 more locks to be shared for all the data in the other files. Space management work will never interfere with the rest of the database.
|
See Also:
Oracle8i Parallel Server Concepts and Administration for a thorough discussion of PCM locks and locking parameters. |
Load balancing distributes query server processes to spread CPU and memory use evenly among nodes. It also minimizes communication and remote I/O among nodes. Oracle does this by allocating servers to the nodes that are running the fewest number of processes.
The load balancing algorithm attempts to maintain an even load across all nodes. For example, if a DOP of 8 is requested on an 8-node MPP (Massively Parallel Processing) system with 1 CPU per node, the algorithm places 2 servers on each node.
If the entire query server group fits on one node, the load balancing algorithm places all the processes on a single node to avoid communications overhead. For example, if a DOP of 8 is requested on a 2-node cluster with 16 CPUs per node, the algorithm places all 16 query server processes on one node.
A user or the DBA can control which instances allocate query server processes by using "Instance Group" functionality. To use this feature, you must first assign each active instance to at least one or more instance groups. Then you can dynamically control which instances spawn parallel processes by activating a particular group of instances.
Establish instance group membership on an instance-by-instance basis by setting the initialization parameter INSTANCE_GROUPS to a name representing one or more instance groups. For example, on a 32-node MPP system owned by both a Marketing and a Sales organization, you could assign half the nodes to one organization and the other half to the other organization using instance group names. To do this, assign nodes 1-16 to the Marketing organization using the following parameter syntax in each INIT.ORA file:
INSTANCE_GROUPS=marketing
Then assign nodes 17-32 to Sales using this syntax in the remaining INIT.ORA files:
INSTANCE_GROUPS=sales
Then a user or the DBA can activate the nodes owned by Sales to spawn query server process by entering the following:
ALTER SESSION SET PARALLEL_INSTANCE_GROUP = 'sales';
In response, Oracle allocates query server processes to nodes 17-32. The default value for PARALLEL_INSTANCE_GROUP is all active instances.
Some OPS platforms use disk affinity. Without disk affinity, Oracle tries to balance the allocation evenly across instances; with disk affinity, Oracle tries to allocate parallel execution servers for parallel table scans on the instances that are closest to the requested data. Disk affinity minimizes data shipping and internode communication on a shared nothing architecture. Disk affinity can thus significantly increase parallel operation throughput and decrease response time.
Disk affinity is used for parallel table scans, parallel temporary tablespace allocation, parallel DML, and parallel index scan. It is not used for parallel table creation or parallel index creation. Access to temporary tablespaces preferentially uses local datafiles. It guarantees optimal space management extent allocation. Disks striped by the operating system are treated by disk affinity as a single unit.
In the following example of disk affinity, table T is distributed across 3 nodes, and a full table scan on table T is being performed.
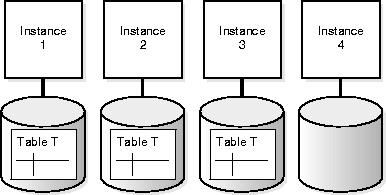
Oracle8i Parallel Server Concepts and Administration for more information on instance affinity.
See Also:
This section describes performance techniques for parallel operations.
The default DOP is appropriate for reducing response time while guaranteeing use of CPU and I/O resources for any parallel operations. If an operation is I/O bound, consider increasing the default DOP. If it is memory bound, or several concurrent parallel operations are running, you might want to decrease the default DOP.
Oracle uses the default DOP for tables that have PARALLEL attributed to them in the data dictionary, or when the PARALLEL hint is specified. If a table does not have parallelism attributed to it, or has NOPARALLEL (the default) attributed to it, then that table is never scanned in parallel--regardless of the default DOP that would be indicated by the number of CPUs, instances, and devices storing that table.
Use the following guidelines when adjusting the DOP:
For example, assume a parallel indexed nested loop join is I/O bound performing the index lookups, with #CPUs=10 and #disks=36. The default DOP is 10, and this is I/O bound. You could first try a DOP of 12. If the application is still I/O bound, try a DOP of 24; if still I/O bound, try 36.
The most important issue for parallel execution is ensuring that all parts of the query plan that process a substantial amount of data execute in parallel. Use EXPLAIN PLAN to verify that all plan steps have an OTHER_TAG of PARALLEL_TO_PARALLEL, PARALLEL_TO_SERIAL, PARALLEL_COMBINED_WITH_PARENT, or PARALLEL_COMBINED_WITH_CHILD. Any other keyword (or null) indicates serial execution, and a possible bottleneck.
By making the following changes you can increase the optimizer's ability to generate parallel plans:
SELECT COUNT(DISTINCT C) FROM T;
To:
SELECT COUNT(*)FROM (SELECT DISTINCT C FROM T);
Oracle cannot return results to a user process in parallel. If a query returns a large number of rows, execution of the query may indeed be faster; however, the user process can only receive the rows serially. To optimize parallel execution performance with queries that retrieve large result sets, use PARALLEL CREATE TABLE ... AS SELECT or direct-load insert to store the result set in the database. At a later time, users can view the result set serially.
When combined with the NOLOGGING option, the parallel version of CREATE TABLE ... AS SELECT provides a very efficient intermediate table facility.
For example:
CREATE TABLE summary PARALLEL NOLOGGING AS SELECT dim_1, dim_2 ..., SUM (meas_1) FROM facts GROUP BY dim_1, dim_2;
These tables can also be incrementally loaded with parallel insert. You can take advantage of intermediate tables using the following techniques:
Consider a large table of retail sales data that is joined to region and to department lookup tables. There are 5 regions and 25 departments. If the huge table is joined to regions using parallel hash partitioning, the maximum speedup is 5. Similarly, if the huge table is joined to departments, the maximum speedup is 25. But if a temporary table containing the Cartesian product of regions and departments is joined with the huge table, the maximum speedup is 125.
Multiple processes can work together simultaneously to create an index. By dividing the work necessary to create an index among multiple server processes, the Oracle Server can create the index more quickly than if a single server process created the index sequentially.
Parallel index creation works in much the same way as a table scan with an ORDER BY clause. The table is randomly sampled and a set of index keys is found that equally divides the index into the same number of pieces as the DOP. A first set of query processes scans the table, extracts key, ROWID pairs, and sends each pair to a process in a second set of query processes based on key. Each process in the second set sorts the keys and builds an index in the usual fashion. After all index pieces are built, the parallel coordinator simply concatenates the pieces (which are ordered) to form the final index.
Parallel local index creation uses a single server set. Each server process in the set is assigned a table partition to scan, and to build an index partition for. Because half as many server processes are used for a given DOP, parallel local index creation can be run with a higher DOP.
You can optionally specify that no redo and undo logging should occur during index creation. This can significantly improve performance, but temporarily renders the index unrecoverable. Recoverability is restored after the new index is backed up. If your application can tolerate this window where recovery of the index requires it to be re-created, then you should consider using the NOLOGGING option.
The PARALLEL clause in the CREATE INDEX statement is the only way in which you can specify the DOP for creating the index. If the DOP is not specified in the parallel clause of CREATE INDEX, then the number of CPUs is used as the DOP. If there is no parallel clause, index creation is done serially.
When you add or enable a UNIQUE key or PRIMARY KEY constraint on a table, you cannot automatically create the required index in parallel. Instead, manually create an index on the desired columns using the CREATE INDEX statement and an appropriate PARALLEL clause and then add or enable the constraint. Oracle then uses the existing index when enabling or adding the constraint.
Multiple constraints on the same table can be enabled concurrently and in parallel if all the constraints are already in the enabled novalidate state. In the following example, the ALTER TABLE ... ENABLE CONSTRAINT statement performs the table scan that checks the constraint in parallel:
CREATE TABLE a (a1 NUMBER CONSTRAINT ach CHECK (a1 > 0) ENABLE NOVALIDATE) PARALLEL; INSERT INTO a values (1); COMMIT; ALTER TABLE a ENABLE CONSTRAINT ach;
|
See Also:
For more information on how extents are allocated when using the parallel execution feature, see Oracle8i Concepts. Also refer to the Oracle8i SQL Reference for the complete syntax of the CREATE INDEX statement. |
This section provides an overview of parallel DML functionality.
Oracle8i Concepts for a detailed discussion of parallel DML and DOP. For a discussion of parallel DML affinity, please see Oracle8i Parallel Server Concepts and Administration.
See Also:
Oracle INSERT functionality can be summarized as follows:
| Insert Type | Parallel | Serial | NOLOGGING |
|
Conventional |
No |
Yes |
No |
|
Direct Load Insert (Append) |
Yes: requires: |
Yes: requires: |
Yes: requires: |
If parallel DML is enabled and there is a PARALLEL hint or PARALLEL attribute set for the table in the data dictionary, then inserts are parallel and appended, unless a restriction applies. If either the PARALLEL hint or PARALLEL attribute is missing, then the insert is performed serially.
Append mode is the default during a parallel insert: data is always inserted into a new block which is allocated to the table. Therefore the APPEND hint is optional. You should use append mode to increase the speed of insert operations--but not when space utilization needs to be optimized. You can use NOAPPEND to override append mode.
The APPEND hint applies to both serial and parallel insert: even serial inserts are faster if you use this hint. APPEND, however, does require more space and locking overhead.
You can use NOLOGGING with APPEND to make the process even faster. NOLOGGING means that no redo log is generated for the operation. NOLOGGING is never the default; use it when you wish to optimize performance. It should not normally be used when recovery is needed for the table or partition. If recovery is needed, be sure to take a backup immediately after the operation. Use the ALTER TABLE [NO]LOGGING statement to set the appropriate value.
When the table or partition has the PARALLEL attribute in the data dictionary, that attribute setting is used to determine parallelism of INSERT, UPDATE, and DELETE statements as well as queries. An explicit PARALLEL hint for a table in a statement overrides the effect of the PARALLEL attribute in the data dictionary.
You can use the NOPARALLEL hint to override a PARALLEL attribute for the table in the data dictionary. In general, hints take precedence over attributes.
DML operations are considered for parallelization only if the session is in a PARALLEL DML enabled mode. (Use ALTER SESSION ENABLE PARALLEL DML to enter this mode.) The mode does not affect parallelization of queries or of the query portions of a DML statement.
In the INSERT... SELECT statement you can specify a PARALLEL hint after the INSERT keyword, in addition to the hint after the SELECT keyword. The PARALLEL hint after the INSERT keyword applies to the insert operation only, and the PARALLEL hint after the SELECT keyword applies to the select operation only. Thus parallelism of the INSERT and SELECT operations are independent of each other. If one operation cannot be performed in parallel, it has no effect on whether the other operation can be performed in parallel.
The ability to parallelize INSERT causes a change in existing behavior, if the user has explicitly enabled the session for parallel DML, and if the table in question has a PARALLEL attribute set in the data dictionary entry. In that case existing INSERT ... SELECT statements that have the select operation parallelized may also have their insert operation parallelized.
If you query multiple tables, you can specify multiple SELECT PARALLEL hints and multiple PARALLEL attributes.
Example
Add the new employees who were hired after the acquisition of ACME.
INSERT /*+ PARALLEL(EMP) */ INTO EMP SELECT /*+ PARALLEL(ACME_EMP) */ * FROM ACME_EMP;
The APPEND keyword is not required in this example, because it is implied by the PARALLEL hint.
The PARALLEL hint (placed immediately after the UPDATE or DELETE keyword) applies not only to the underlying scan operation, but also to the update/delete operation. Alternatively, you can specify update/delete parallelism in the PARALLEL clause specified in the definition of the table to be modified.
If you have explicitly enabled PDML (Parallel Data Manipulation Language) for the session or transaction, UPDATE/DELETE statements that have their query operation parallelized may also have their UPDATE/DELETE operation parallelized. Any subqueries or updatable views in the statement may have their own separate parallel hints or clauses, but these parallel directives do not affect the decision to parallelize the update or delete. If these operations cannot be performed in parallel, it has no effect on whether the UPDATE or DELETE portion can be performed in parallel.
You can only use parallel UPDATE and DELETE on partitioned tables.
Example 1
Give a 10% salary raise to all clerks in Dallas.
UPDATE /*+ PARALLEL(EMP) */ EMP SET SAL=SAL * 1.1 WHERE JOB='CLERK' AND DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE LOCATION='DALLAS');
The PARALLEL hint is applied to the update operation as well as to the scan.
Example 2
Fire all employees in the accounting department, whose work will be outsourced.
DELETE /*+ PARALLEL(EMP) */ FROM EMP WHERE DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE DNAME='ACCOUNTING');
Again, the parallelism is applied to the scan as well as update operation on table EMP.
Parallel DML combined with the updatable join views facility provides an efficient solution for refreshing the tables of a data warehouse system. To refresh tables is to update them with the differential data generated from the OLTP production system.
In the following example, assume that you want to refresh a table named CUSTOMER(c_key, c_name, c_addr). The differential data contains either new rows or rows that have been updated since the last refresh of the data warehouse. In this example, the updated data is shipped from the production system to the data warehouse system by means of ASCII files. These files must be loaded into a temporary table, named DIFF_CUSTOMER, before starting the refresh process. You can use SQL Loader with both the parallel and direct options to efficiently perform this task.
Once DIFF_CUSTOMER is loaded, the refresh process can be started. It is performed in two phases:
A straightforward SQL implementation of the update uses subqueries:
UPDATE CUSTOMER SET(C_NAME, C_ADDR) = (SELECT C_NAME, C_ADDR FROM DIFF_CUSTOMER WHERE DIFF_CUSTOMER.C_KEY = CUSTOMER.C_KEY) WHERE C_KEY IN(SELECT C_KEY FROM DIFF_CUSTOMER);
Unfortunately, the two subqueries in the preceding statement affect the performance.
An alternative is to rewrite this query using updatable join views. To do this you must first add a primary key constraint to the DIFF_CUSTOMER table to ensure that the modified columns map to a key-preserved table:
CREATE UNIQUE INDEX DIFF_PKEY_IND ON DIFF_CUSTOMER(C_KEY) PARALLEL NOLOGGING; ALTER TABLE DIFF_CUSTOMER ADD PRIMARY KEY (C_KEY);
Update the CUSTOMER table with the following SQL statement:
UPDATE /*+ PARALLEL(CUST_JOINVIEW) */ (SELECT /*+ PARALLEL(CUSTOMER) PARALLEL(DIFF_CUSTOMER) */ CUSTOMER.C_NAME as C_NAME CUSTOMER.C_ADDR as C_ADDR, DIFF_CUSTOMER.C_NAME as C_NEWNAME, DIFF_CUSTOMER.C_ADDR as C_NEWADDR WHERE CUSTOMER.C_KEY = DIFF_CUSTOMER.C_KEY) CUST_JOINVIEW SET C_NAME = C_NEWNAME, C_ADDR = C_NEWADDR;
The base scans feeding the join view CUST_JOINVIEW are done in parallel. You can then parallelize the update to further improve performance but only if the CUSTOMER table is partitioned.
|
See Also:
"Rewriting SQL Statements". Also see the Oracle8i Application Developer's Guide - Fundamentals for information about key-preserved tables. |
The last phase of the refresh process consists in inserting the new rows from the DIFF_CUSTOMER to the CUSTOMER table. Unlike the update case, you cannot avoid having a subquery in the insert statement:
INSERT /*+PARALLEL(CUSTOMER)*/ INTO CUSTOMER SELECT * FROM DIFF_CUSTOMER WHERE DIFF_CUSTOMER.C_KEY NOT IN (SELECT /*+ HASH_AJ */ KEY FROM CUSTOMER);
But here, the HASH_AJ hint transforms the subquery into an anti-hash join. (The hint is not required if the parameter ALWAYS_ANTI_JOIN is set to hash in the initialization file). Doing so allows you to use parallel insert to execute the preceding statement very efficiently. Parallel insert is applicable even if the table is not partitioned.
Cost-based optimization is a highly sophisticated approach to finding the best execution plan for SQL statements. Oracle automatically uses cost-based optimization with parallel execution.
Use discretion in employing hints. If used, hints should come as a final step in tuning, and only when they demonstrate a necessary and significant performance advantage. In such cases, begin with the execution plan recommended by cost-based optimization, and go on to test the effect of hints only after you have quantified your performance expectations. Remember that hints are powerful; if you use them and the underlying data changes you may need to change the hints. Otherwise, the effectiveness of your execution plans may deteriorate.
Always use cost-based optimization unless you have an existing application that has been hand-tuned for rule-based optimization. If you must use rule-based optimization, rewriting a SQL statement can greatly improve application performance.
Use the decision tree in Figure 27-6 to diagnose parallel performance problems. The questions in the decision points of Figure 27-6 are discussed in more detail after the figure.
Some key issues in diagnosing parallel execution performance problems are the following:
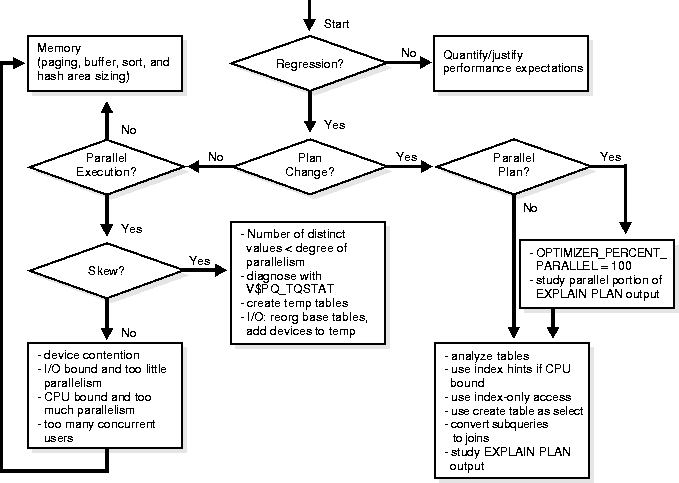
Does parallel execution's actual performance deviate from what you expected? If performance is as you expected, could there be an underlying performance problem? Perhaps you have a desired outcome in mind to which you are comparing the current outcome. Perhaps you have justifiable performance expectations that the system does not achieve. You might have achieved this level of performance or particular execution plan in the past, but now, with a similar environment and operation, your system is not meeting this goal.
If performance is not as you expected, can you quantify the deviation? For data warehousing operations, the execution plan is key. For critical data warehousing operations, save the EXPLAIN PLAN results. Then, as you analyze the data, reanalyze, upgrade Oracle, and load new data, over time you can compare new execution plans with old plans. Take this approach either proactively or reactively.
Alternatively, you may find that plan performance improves if you use hints. You may want to understand why hints were necessary, and determine how to get the optimizer to generate the desired plan without the hints. Try increasing the statistical sample size: better statistics may give you a better plan. If you had to use a PARALLEL hint, determine whether you had OPTIMIZER_PERCENT_PARALLEL set to 100%.
|
See Also:
For more information on the EXPLAIN PLAN statement, refer to Chapter 13, "Using EXPLAIN PLAN". For information on preserving plans throughout changes to your system using Plan Stability and outlines, please refer to Chapter 7, "Optimizer Modes, Plan Stability, and Hints". |
If there has been a change in the execution plan, determine whether the plan is (or should be) parallel or serial.
If the execution plan is or should be parallel:
If the execution plan is or should be serial, consider the following strategies:
If the cause of regression cannot be traced to problems in the plan, then the problem must be an execution issue. For data warehousing operations, both serial and parallel, consider how your plan uses memory. Check the paging rate and make sure the system is using memory as effectively as possible. Check buffer, sort, and hash area sizing. After you run a query or DML operation, look at the V$SESSTAT, V$PX_SESSTAT, and V$PQ_SYSSTAT views to see the number of server processes used and other information for the session and system.
If you are using parallel execution, is there unevenness in workload distribution? For example, if there are 10 CPUs and a single user, you can see whether the workload is evenly distributed across CPUs. This may vary over time, with periods that are more or less I/O intensive, but in general each CPU should have roughly the same amount of activity.
The statistics in V$PQ_TQSTAT show rows produced and consumed per parallel execution server. This is a good indication of skew and does not require single user operation.
Operating system statistics show you the per-processor CPU utilization and per-disk I/O activity. Concurrently running tasks make it harder to see what is going on, however. It can be useful to run in single-user mode and check operating system monitors that show system level CPU and I/O activity.
When workload distribution is unbalanced, a common culprit is the presence of skew in the data. For a hash join, this may be the case if the number of distinct values is less than the degree of parallelism. When joining two tables on a column with only 4 distinct values, you will not get scaling on more than 4. If you have 10 CPUs, 4 of them will be saturated but 6 will be idle. To avoid this problem, change the query: use temporary tables to change the join order such that all operations have more values in the join column than the number of CPUs.
If I/O problems occur you may need to reorganize your data, spreading it over more devices. If parallel execution problems occur, check to be sure you have followed the recommendation to spread data over at least as many devices as CPUs.
If there is no skew in workload distribution, check for the following conditions: