Table of Contents
- 9.1. Revisions
- 9.2. Introduction
- 9.3. URIs, literals and variables
- 9.4. Path expressions
- 9.5. Select- and construct queries
- 9.6. Select queries
- 9.7. Construct queries
- 9.8. The WHERE clause
- 9.9. Other functions
- 9.10. The ORDER BY clause
- 9.11. The LIMIT and OFFSET clauses
- 9.12. The USING NAMESPACE clause
- 9.13. Built-in predicates (REVISED in R2.0)
- 9.14. Set combinatory operations
- 9.15. Query Nesting
- 9.16. Querying context (R2.0)
- 9.17. Example SeRQL queries
- 9.18. References
- 9.19. SeRQL grammar
SeRQL revision 1.1 is a syntax revision (see issue tracker item SES-75). This document describes the revised syntax. From Sesame release 1.2-RC1 onwards, the old syntax is no longer supported.
SeRQL revision 1.2 covers a set of new functions and operators:
- Specification of blank node identifiers (Section 9.3.4, “Blank Nodes (R1.2)”).
- Case sensitive string matching (Section 9.8.7, “Like (R1.2)”).
- New functions isBNode(), isURI() (Section 9.8.6, “isUri() and isBnode() (R1.2)”).
- Nested WHERE clause for optional path expressions (Section 9.8.12, “Nested WHERE clauses (R1.2)”).
- New functions namespace(), localName() (Section 9.9.2, “namespace() and localName() (R1.2)”).
- OWL default namespace (Section 9.12, “The USING NAMESPACE clause”).
- Set operations (Section 9.14, “Set combinatory operations”).
- Nested queries (Section 9.15, “Query Nesting”).
- Set membership operator (Section 9.15.1, “IN (R1.2)”).
- ANY and ALL keywords (Section 9.15.2, “ANY and ALL (R1.2)”).
- Existential quantification (Section 9.15.3, “EXISTS (R1.2)”).
New operations have been marked with (R1.2) where appropriate in this document.
SeRQL revision 2.0 is an extension of SeRQL that offers functionality for querying contexts. See Section 9.16, “Querying context (R2.0)” for details.
SeRQL revision 3.0 modifies SeRQL to be more like SPARQL, adopting its semantics and operators. Main backwards compatiblity issues with revision 2.0 are:
- The NULL value has been deprecated; the BOUND-operator should now be used instead. For now, the SeRQL parser will automatically translate NULL values to BOUND-operators as much as possible.
- The semantics of optional joins have been changed from the existing iterative semantics to the better defined compositional semantics that is used in SPARQL. This change will only affect some corner cases that are unlikely to appear in actual queries.
SeRQL revision 3.1 adds the possibility to apply the IN-operator on a list of values. It also adds support for some SPARQL functionality that wasn't available in SeRQL (in whatever form). This includes the SAMETERM, STR, LANGMATCHES and REGEX operators, result ordering using ORDER BY, UNION of path expressions and the REDUCED modifier for both select and construct queries. SeRQL revision 3.1 was implemented in Sesame 2.3.0.
SeRQL ("Sesame RDF Query Language", pronounced "circle") is an RDF query language that is very similar to SPARQL, but with other syntax. SeRQL was originally developed as a better alternative for the query languages RQL and RDQL. A lot of SeRQL's features can now be found in SPARQL and SeRQL has adopted some of SPARQL's features in return.
This document briefly shows all of these features. After reading through this document one should be able to write SeRQL queries.
URIs and literals are the basic building blocks of RDF. For a query language like SeRQL, variables are added to this list. The following sections will show how to write these down in SeRQL.
Variables are identified by names. These names must start with a letter or an underscore ('_') and can be followed by zero or more letters, numbers, underscores, dashes ('-') or dots ('.'). Examples variable names are:
- Var1
- _var2
- unwise.var-name_isnt-it
SeRQL keywords are not allowed to be used as variable names. Currently, the following keywords are used in SeRQL: select, construct, distinct, reduced, as, from, context, where, order, by, asc, desc, limit, offset, using, namespace, true, false, not, and, or, sameterm, like, ignore, case, regex, label, lang, langmatches, datatype, localname, str, bound, null, isresource, isbnode, isuri, isliteral, in, union, intersect, minus, exists, any, all.
Keywords in SeRQL are all case-insensitive but variable names are case-sensitive.
There are two ways to write down URIs in SeRQL: either as full URIs or as abbreviated URIs. Full URIs must be surrounded with "<" and ">". Examples of this are:
- <http://www.openrdf.org/index.html>
- <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
- <mailto:sesame@openrdf.org>
- <file:///C:\rdffiles\test.rdf>
As URIs tend to be long strings with the first part being shared by several of them (i.e. the namespace), SeRQL allows one to use abbreviated URIs (or QNames) by defining (short) names for these namespaces which are called "prefixes". A QName always starts with one of the defined prefixes and a colon (":"). After this colon, the part of the URI that is not part of the namespace follows. The first part, consisting of the prefix and the colon, is replaced by the full namespace by the query engine. Some example QNames are:
- sesame:index.html
- rdf:type
- foaf:Person
RDF literals consist of three parts: a label, a language tag, and a datatype. The language tag and the datatype are optional and at most one of these two can accompany a label (a literal can not have both a language tag and a datatype). The notation of literals in SeRQL has been modelled after their notation in N-Triples; literals start with the label, which is surrounded by double quotes, optionally followed by a language tag with a "@" prefix or by a datatype URI with a "^^" prefix. Example literals are:
- "foo"
- "foo"@en
- "<foo/>"^^<http://www.w3.org/1999/02/22-rdf-syntax-ns#XMLLiteral>
The SeRQL notation for abbreviated URIs can also be used. When the prefix rdf is mapped to the namespace http://www.w3.org/1999/02/22-rdf-syntax-ns#, the last example literal could also have been written down like:
- "<foo/>"^^rdf:XMLLiteral
SeRQL has also adopted the character escapes from N-Triples; special characters can be escaped by prefixing them with a backslash. One of the special characters is the double quote. Normally, a double quote would signal the end of a literal's label. If the double quote is part of the label, it needs to be escaped. For example, the sentence John said: "Hi!" can be encoded in a SeRQL literals as: "John said: \"Hi!\"".
As the backslash is a special character itself, it also needs to be escaped. To encode a single backslash in a literal's label, two backslashes need to be written in the label. For example, a Windows directory would be encoded as: "C:\\Program Files\\Apache Tomcat\\".
SeRQL has functions for extracting each of the three parts of a literal. These functions are label, lang, and datatype. label("foo"@en) extracts the label "foo", lang("foo"@en) extracts the language tag "en", and datatype("foo"^^rdf:XMLLiteral) extracts the datatype rdf:XMLLiteral. The use of these functions is explained later.
RDF has a notion of blank nodes. These are nodes in the RDF graph that are not labeled with a URI or a literal. The interpretation of such blank nodes is as a form of existential quantification: it allows one to assert that "there exists a node such that..." without specifying what that particular node is. Blank nodes do in fact often have identifiers, but these identifiers are assigned internally by whatever processor is processing the graph and they are only valid in the local context, not as global identifiers (unlike URIs).
Strictly speaking blank nodes are only addressable indirectly, by querying for one or more properties of the node. However, SeRQL, as a practical shortcut, allows blank node identifiers to be used in queries. The syntax for blank nodes is adopted from N-Triples, using a QName-like syntax with "_" as the namespace prefix, and the internal blank node identifier as the local name. For example:
- _:bnode1
This identifies the blank node with internal identifier "bnode1". These blank node identifiers can be used in the same way that normal URIs or QNames can be used.
Caution: It is important to realize that addressing blank nodes in this way makes SeRQL queries non-portable across repositories. There is no guarantee that in two repositories, even if they contain identical datasets, the blank node identifiers will be identical. It may well be that "bnode1" in repository A is a completely different blank node than "bnode1" in repository B. Even in the same repository, it is not guaranteed that blank node identifiers are stable over updates: if certain statements are added to or removed from a repository, it is not guaranteed "bnode1" still identifies the same blank node that it did before the update operation.
One of the most prominent parts of SeRQL are path expressions. Path expressions are expressions that match specific paths through an RDF graph.
Imagine that we want to query an RDF graph for persons who work for companies that are IT companies. Querying for this information comes down to finding the following pattern in the RDF graph (gray nodes denote variables):

The SeRQL notation for path expressions resembles the picture above; it is written down as:
{Person} foo:worksFor {Company} rdf:type {foo:ITCompany}The parts surrounded by curly brackets represent the nodes in the RDF graph, the parts between these nodes represent the edges in the graph. The direction of the arcs (properties) in SeRQL path expressions is always from left to right.
In SeRQL queries, multiple path expressions can be specified by seperating them with commas. For example, the path expression show before can also be written down as two smaller path expressions:
{Person} foo:worksFor {Company},
{Company} rdf:type {foo:ITCompany}The nodes and edges in the path expressions can be variables, URIs and literals. Also, a node can be left empty in case one is not interested in the value of that node. Here are some more example path expressions to illustrate this:
- {Person} foo:worksFor {} rdf:type {foo:ITCompany}
- {Painting} ex:painted_by {} ex:name {"Picasso"}
- {comic:RoadRunner} SomeRelation {foo:WillyECoyote}
Each and every path can be constructed using a set of basic path expressions. Sometimes, however, it is nicer to use one of the available short cuts. There are three types of short cuts:
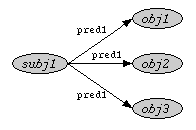
In situations where one wants to query for two or more statements with identical subject and predicate, the subject and predicate do not have to be repeated over and over again. Instead, a multi-value node can be used:
{subj1} pred1 {obj1, obj2, obj3}A built-in constraint on this construction is that each value for the variables in the multi-value node is unique (i.e. they are pairwise disjoint). Therefore, this path expression is equivalent to the following combination of path expressions and boolean constraints:
FROM
{subj1} pred1 {obj1},
{subj1} pred1 {obj2},
{subj1} pred1 {obj3}
WHERE obj1 != obj2 AND obj1 != obj3 AND obj2 != obj3Or graphically:
Multi-value nodes can also be used when statements share the predicate and object, e.g.:
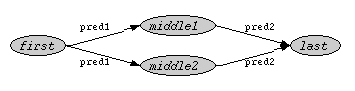
{subj1, subj2, subj3} pred1 {obj1}When used in a longer path expression, multi-value nodes apply to both the part left of the node and the part right of the node. The following path expression:
{first} pred1 {middle1, middle2} pred2 {last}matches the following graph:
One of the shorts cuts that is probably used most, is the notation for branches in path expressions. There are lots of situations where one wants to query multiple properties of a single subject. Instead of repeating the subject over and over again, one can use a semi-colon to attach a predicate-object combination to the subject of the last part of a path expression, e.g.:
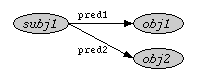
{subj1} pred1 {obj1};
pred2 {obj2}Which is equivalent to:
{subj1} pred1 {obj1},
{subj1} pred2 {obj2}Or graphically:
A more advanced example is:
{first} pred {} pred1 {obj1};
pred2 {obj2} pred3 {obj3}Which matches the following graph:

Note that an anonymous variable is used in the middle of the path expressions.
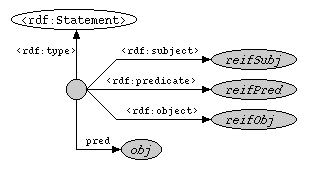
The last short cut is a short cut for reified statements. A path expression representing a single statement (i.e. {node} edge {node}) can be written between the curly brackets of a node, e.g.:
{ {reifSubj} reifPred {reifObj} } pred {obj}This would be equivalent to querying (using "rdf:" as a prefix for the RDF namespace, and "Statement" as a variable for storing the statement's URI):
{Statement} rdf:type {rdf:Statement},
{Statement} rdf:subject {reifSubj},
{Statement} rdf:predicate {reifPred},
{Statement} rdf:object {reifObj},
{Statement} pred {obj}Again, graphically:
Optional path expressions differ from 'normal' path expressions in that they do not have to be matched to find query results. The SeRQL query engine will try to find paths in the RDF graph matching the path expression, but when it cannot find any paths it will skip the expression and leave any variables in it unbound.
Consider an RDF graph that contains information about people that have names, ages, and optionally e-mail addresses. This is a situation that is very common in RDF data. A logical query on this data is a query that yields all names, ages and, when available, e-mail addresses of people, e.g.:
{Person} ex:name {Name};
ex:age {Age};
ex:email {EmailAddress}However, using normal path expressions like in the query above, people without e-mail address will not be included in the query result. With optional path expressions, one can indicate that a specific (part of a) path expression is optional. This is done using square brackets, i.e.:
{Person} ex:name {Name};
ex:age {Age};
[ex:email {EmailAddress}]Or alternatively:
{Person} ex:name {Name};
ex:age {Age},
[{Person} ex:email {EmailAddress}]In contrast to the first path expressions, this expression will also match people without an e-mail address. For these people, the variable EmailAddress will be unbound.
Optional path expressions can also be nested. This is useful in situations where the existence of a specific path is dependent on the existence of another path. For example, the following path expression queries for the titles of all known documents and, if the author of the document is known, the name of the author (if it is known) and his e-mail address (if it is known):
{Document} ex:title {Title};
[ex:author {Author} [ex:name {Name}];
[ex:email {Email}]]With this path expression, the SeRQL query engine will not try to find the name and e-mail address of an author when it cannot even find the resource representing the author.
The SeRQL query language supports two querying concepts. The first one can be characterized as returning a table of values, or a set of variable-value bindings. The second one returns an RDF graph, which can be a subgraph of the graph being queried, or a graph containing information that is derived from it. The first type of queries are called "select queries", the second type of queries are called "construct queries".
A SeRQL query is typically built up from one to seven clauses. For select queries these clauses are: SELECT, FROM, FROM CONTEXT, WHERE, LIMIT, OFFSET and USING NAMESPACE. One might recognize some of these clauses from SQL, but their usage is slightly different. For construct queries the clauses are the same with the exception of the first; construct queries start with a CONSTRUCT clause instead of a SELECT clause. Except for the first clause (SELECT or CONSTRUCT), all clauses are optional.
The first clause (i.e. SELECT or CONSTRUCT) determines what is done with the results that are found. In a SELECT clause, one can specify which variable values should be returned. In a CONSTRUCT clause, one can specify which statements should be returned.
The FROM clause specifies path expressions, which were explained in the previous section. It defines the paths in an RDF graph that are relevant to the query. Note that, when the FROM clause is not specified, the query will simply return the constants specified in the SELECT or CONSTRUCT clause.
The FROM CONTEXT clause is new in SeRQL revision 2.0. It is a variant of the FROM clause that allows one to constrain the path expressions in the clause to one or more contexts. Using context in querying will be explained in more detail in Section 9.16, “Querying context (R2.0)”.
The WHERE clause specifies additional (Boolean) constraints on the values in the path expressions. These are constraints on the nodes and edges of the paths that cannot be expressed in the path expressions themselves.
The LIMIT and OFFSET clauses can be used separately or combined in order to get a subset of all query answers. Their usage is very similar to the LIMIT and OFFSET clauses in SQL queries. The LIMIT clause determines the (maximum) number of query answers that will be returned. The OFFSET clause determines which query answer will be returned as the first result, skipping as many query results as specified in this clause.
Finally, the USING NAMESPACE clause can be used to declare namespace prefixes. These are the mappings from prefixes to namespaces that were referred to in one of previous sections about (abbreviated) URIs.
The WHERE, LIMIT, OFFSET and USING NAMESPACE clauses will be explained in one of the next sections. The following section will explain the SELECT and FROM clause.
As said before, select queries return tables of values, or sets of variable-value bindings. Which values are returned can be specified in the select clause. One can specify variables and/or values in the select clause, seperated by commas. The following example query returns all URIs of classes:
SELECT C
FROM {C} rdf:type {rdfs:Class}It is also possible to use a '*' in the SELECT clause. In that case, all variable values will be returned, e.g.:
SELECT *
FROM {S} rdfs:label {O}This query will return the values of the variables S and O.
SELECT O, S
FROM {S} rdfs:label {O}By default, the results of a select query are not filtered for duplicate rows. Because of the nature of the above queries, these queries will never return duplicates. However, more complex queries might result in duplicate result rows. These duplicates can be filtered out by the SeRQL query engine. To enable this functionality, one needs to specify the DISTINCT keyword after the select keyword. For example:
SELECT DISTINCT *
FROM {Country1} ex:borders {} ex:borders {Country2}
USING NAMESPACE
ex = <http://example.org/things#>An alternative to DISTINCT is the REDUCED keyword (Since R3.1). Specifying the REDUCED keyword allows the query engine to filter duplicates from the results, but does not require or guarantee that all duplicates are eliminated. In some cases specifying this keyword allows the query engine to apply more extensive query optimizations, resulting in better query performance. Specifying this option is recommended if there are no strong requirements to retrieve all duplicates.
Construct queries return RDF graphs as set of statements. The statements that a query should return can be specified in the construct clause using the previously explained path expressions. The following is an example construct query:
CONSTRUCT {Parent} ex:hasChild {Child}
FROM {Child} ex:hasParent {Parent}
USING NAMESPACE
ex = <http://example.org/things#>This query defines the inverse of the property ex:hasParent to be ex:hasChild. This is just one example of a query that produces information that is derived from the original information. Here is one more example:
CONSTRUCT
{Artist} rdf:type {ex:Painter};
ex:hasPainted {Painting}
FROM
{Artist} rdf:type {ex:Artist};
ex:hasCreated {Painting} rdf:type {ex:Painting}
USING NAMESPACE
ex = <http://example.org/things#>This query derives that an artist who has created a painting, is a painter. The relation between the painter and the painting is modelled to be art:hasPainted.
Instead of specifying a path expression in the CONSTRUCT clause, one can also use a '*'. In that case, the CONSTRUCT clause is identical to the FROM clause. This allows one to extract a subgraph from a larger graph, e.g.:
CONSTRUCT *
FROM {SUB} rdfs:subClassOf {SUPER}This query extracts all rdfs:subClassOf relations from an RDF graph.
Just like with select queries, the results of a construct query are not filtered for duplicate statements by default. Again, these duplicates are filtered out by the SeRQL query engine if the DISTINCT keyword is specified after the construct keyword, for example:
CONSTRUCT DISTINCT
{Artist} rdf:type {ex:Painter}
FROM
{Artist} rdf:type {ex:Artist};
ex:hasCreated {} rdf:type {ex:Painting}
USING NAMESPACE
ex = <http://example.org/things#>Again, the REDUCED keyword can also be used as an alternative to DISTINCT. See Section 9.6, “Select queries” for a description of this keyword.
The third clause in a query is the WHERE clause. This is an optional clause in which one can specify Boolean constraints on variables.
The following sections will explain the available Boolean expressions for use in the WHERE clause. Section 9.8.12, “Nested WHERE clauses (R1.2)” will explain how WHERE clauses can be nested inside optional path expressions.
There are two Boolean constants, TRUE and FALSE. The first one is simply always true, the last one is always false. The following query will never produce any results because the constraint in the where clause will never evaluate to true:
SELECT *
FROM {X} Y {Z}
WHERE FALSEThe most common boolean constraint is equality or inequality of values. Values can be compared using the operators "=" (equality) and "!=" (inequality). The expression
Var = <foo:bar>
is true if the variable Var has been bound to the URI <foo:bar>, and the expression
Var1 != Var2
checks whether two variables are bound to unequal values.
Equality of literals is influenced by the literal's datatype. This means that two values that represent the same value but are written differently still compare equal. For example, the following comparison evaluates to true:
"123"^^xsd:positiveInteger = "123.0"^^xsd:float
Where the equality operators described in the previous section compares values taking datatypes into account, the SameTerm operator requires an exact lexical match of values. Using a SameTerm operator on a variable and a value is equivalent to replacing the variable with the value in all path expressions. For exampe, the following query:
SELECT X, Y
FROM {X} Y {Z}
WHERE SameTerm(Z, "123.0"^^xsd:float)...is equivalent to:
SELECT X, Y
FROM {X} Y {"123.0"^^xsd:float}...but is semantically different from:
SELECT X, Y
FROM {X} Y {Z}
WHERE Z = "123.0"^^xsd:floatNumbers can be compared to each other using the operators "<" (lower than), "<=" (lower than or equal to), ">" (greater than) and ">=" (greater than or equal to). SeRQL uses a literal's datatype to determine whether its value is numerical. All XML Schema built-in numerical datatypes are supported, i.e.: xsd:float, xsd:double, xsd:decimal and all subtypes of xsd:decimal (xsd:long, xsd:nonPositiveInteger, xsd:byte, etc.), where the prefix xsd is used to reference the XML Schema namespace.
In the following query, a comparison between values of type xsd:positiveInteger is used to retrieve all countries that have a population of less than 1 million:
SELECT Country
FROM {Country} ex:population {Population}
WHERE Population < "1000000"^^xsd:positiveInteger
USING NAMESPACE
ex = <http://example.org/things#>If one want to compare values of incompatible types, one can try to cast one or both of the values to another type. For example in the above query, if the values that Population is bound to generally do not have a datatype, one can cast these values to xsd:integer to make the comparison work, e.g.:
SELECT Country
FROM {Country} ex:population {Population}
WHERE xsd:integer(Population) < "1000000"^^xsd:positiveInteger
USING NAMESPACE
ex = <http://example.org/things#>SeRQL supports all value casting methods from SPARQL, see SPARQL's Constructor Functions for more details.
The bound() boolean function checks whether a specific variable has been bound to a value. For example, the following query returns the names of all people without a (known) e-mail address.
SELECT Name
FROM {Person} foaf:name {Name};
[ex:email {EmailAddress}]
WHERE NOT BOUND(EmailAddress)
The isURI() and isBNode() boolean functions are more specific versions of isResource(). They check whether a variable is bound to a URI value or a BNode value, respectively. For example, the following query returns only URIs (and filters out all bNodes and literals):
SELECT V
FROM {R} prop {V}
WHERE isURI(V)The LIKE operator can check whether a value matches a specified pattern of characters. '*' characters can be used as wildcards, matching with zero or more characters. The rest of the characters are compared lexically. The pattern is surrounded with double quotes, just like a literal's label.
SELECT Country
FROM {Country} ex:name {Name}
WHERE Name LIKE "Belgium"
USING NAMESPACE
ex = <http://example.org/things#>By default, the LIKE operator does a case-sensitive comparison: in the above query, the operator fails is the variable Name is bound to the value "belgium" instead of "Belgium". Optionally, one can specify that the operator should perform a case-insensitive comparison:
SELECT Country
FROM {Country} ex:name {Name}
WHERE Name LIKE "belgium" IGNORE CASE
USING NAMESPACE
ex = <http://example.org/things#>In this query, the operator will succeed for "Belgium", "belgium", "BELGIUM", etc.
The '*' character can be used as a wildcard to indicate substring matches, for example:
SELECT Country
FROM {Country} ex:name {Name}
WHERE Name LIKE "*Netherlands"
USING NAMESPACE
ex = <http://example.org/things#>This query will match any country names that end with the string "Netherlands", for example "The Netherlands".
The regex() function in SeRQL has been adopted from SPARQL. See the SPARQL regex description for more information.
The langMatches() function in SeRQL has been adopted from SPARQL. See the SPARQL langMatches description for more information.
Boolean constraints and functions can be combined using the AND and OR operators, and negated using the NOT operator. The NOT operator has the highest presedence, then the AND operator, and finally the OR operator. Parentheses can be used to override the default presedence of these operators. The following query is a (kind of artifical) example of this:
SELECT *
FROM {X} Prop {Y} rdfs:label {L}
WHERE NOT L LIKE "*FooBar*" AND
(Y = <foo:bar> OR Y = <bar:foo>) AND
isLiteral(L)The IN operator can check whether a value is contained in a list of one or more other values. For example:
SELECT *
FROM {X} Prop {Y}
WHERE Y IN (<foo:bar>, <bar:foo>)When there are multiple alternatives, this syntax is more convenient than the semantic equivalent with a combination of OR and SameTerm operators:
SELECT *
FROM {X} Prop {Y}
WHERE SameTerm(Y, <foo:bar>) OR SameTerm(Y, <bar:foo>)In order to be able to express boolean constraints on variables in optional path expressions, it is possible to use a nested WHERE clause. The constraints in such a nested WHERE clause restrict the potential matches of the optional path expressions, without causing the entire query to fail if the boolean constraint fails.
To illustrate the difference between a nested WHERE clause and a 'normal' WHERE clause, consider the following two queries on the same data:
Data (using Turtle format):
@prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix ex: <http://example.org/> . _:a foaf:name "Michael" . _:b foaf:name "Rubens" . _:b ex:email "rubinho@example.work". _:b foaf:name "Giancarlo" . _:b ex:email "giancarlo@example.work".
Query 1 (normal WHERE-clause):
SELECT
Name, EmailAddress
FROM
{Person} foaf:name {Name};
[ex:email {EmailAddress}]
WHERE EmailAddress LIKE "g*"Query 2 (nested WHERE-clause):
SELECT
Name, EmailAddress
FROM
{Person} foaf:name {Name};
[ex:email {EmailAddress} WHERE EmailAddress LIKE "g*"]In query 1, a normal WHERE clause specifies that the EmailAddress found by the optional expression must begin with the letter "g". The result of this query will be:
| Name | EmailAddress |
|---|---|
| Giancarlo | "giancarlo@example.work" |
Despite the fact that the match on EmailAddress is defined as optional, the persons named "Michael" and "Rubens" are not returned. The reason is that the WHERE clause explicitly says that the value bound to the optional variable must start with the letter "g". For Michael, no value is found, hence the variable is unbound, and the comparison operator fails on this. For Rubens, a value is found, but it does not start with the letter "g".
In query 2, however, a nested WHERE-clause is used. This specifies that any binding the optional expression matches must begin with the letter "g". The result of this query is:
| Name | EmailAddress |
|---|---|
| Michael | |
| Rubens | |
| Giancarlo | "giancarlo@example.work" |
The person "Michael" is returned without a result for his email address because there is no email address known for him at all. The person "Rubens" is returned without a result for his email address because, although he does have an email address, it does not start with the letter "g".
A query can contain at most one nested WHERE-clause per optional path expression, and at most one 'normal' WHERE-clause.
Apart from the boolean functions and operators introduced in the previous section, SeRQL supports several other functions that return RDF terms rather than non-boolean values. These functions can be used in both the SELECT and the WHERE clause.
The three functions label(), lang() and datatype() all operate on literals. The result of the label() function is the lexical form of the supplied literal. The lang() function returns the language attribute. Both functions return their result as an untyped literal, which can again be compared with other literals using (in)equality-, comparison-, and like operators. The result of the datatype() function is a URI, which can be compared to other URIs. These functions can also be used in SELECT clauses, but not in path expressions.
An example query:
SELECT label(L)
FROM {R} rdfs:label {L}
WHERE isLiteral(L) AND lang(L) LIKE "en*"The functions namespace() and localName() operate on URIs. The namespace() function returns the namespace of the supplied URI, as a URI object. The localName() function returns the local name part of the supplied URI, as a literal. These functions can also be used in SELECT clauses, but not in path expressions.
The following query retrieves all properties of foaf:Person instances that are in the FOAF namespace. Notice that as a shorthand for the full URI, we can use a namespace prefix (followed by a colon) as an argument.
Data:
@prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix ex: <http://example.org/> . _:a rdf:type foaf:Person . _:a my:nick "Schumi" . _:a foaf:firstName "Michael" . _:a foaf:knows _:b . _:b rdf:type foaf:Person . _:b foaf:firstName "Rubens" . _:b foaf:nick "Rubinho" .
Query:
SELECT foafProp, Value
FROM {} foafProp {Value}
WHERE namespace(foafProp) = foaf:
USING NAMESPACE
foaf = <http://xmlns.com/foaf/0.1/>Result:
| foafProp | Value |
|---|---|
| <http://xmlns.com/foaf/0.1/firstName | "Michael" |
| <http://xmlns.com/foaf/0.1/knows | _:b |
| <http://xmlns.com/foaf/0.1/firstName | "Rubens" |
| <http://xmlns.com/foaf/0.1/nick | "Rubinho" |
In the following example, the localName() function is used to match two equivalent properties from different namespaces (using the above data).
Query:
SELECT nick
FROM {} rdf:type {foaf:Person};
nickProp {nick}
WHERE localName(nickProp) LIKE "nick"
USING NAMESPACE
foaf = <http://xmlns.com/foaf/0.1/>Result:
| nick |
|---|
| "Schumi" |
| "Rubinho" |
The ORDER BY clause can be used to order query results in particular ways. This functionality has been adopted from SPARQL, but the syntax is slightly different. The following example retrieves all known countries, ordered from largest to smallest population:
SELECT Countr, Population
FROM {Country} ex:population {Population}
ORDER BY Population DESC
USING NAMESPACE
ex = <http://example.org/things#>The DESC keyword in this example tells the query engine to sort in the results in descending order. The ASC keyword can be used to sort the results in ascending order, which is also the default when order is specified.
Multiple ordering expressions can be specified. If the first expression doesn't define an order between two results, the query engine will use the second expression. This process continues until an order between the results has been established, or until all ordering expressions have been processed. In the latter case, the order of these results is unspecified.
Please see the SPARQL specification for more information on the (partial) ordering of URIs, literals, etc.
LIMIT and OFFSET allow you to retrieve just a portion of the results that are generated by the query. If a limit count is given, no more than that many results will be returned (but possibly less, if the query itself yields less results).
OFFSET says to skip that many results before beginning to return results. OFFSET 0 is the same as omitting the OFFSET clause. If both OFFSET and LIMIT appear, then OFFSET rows are skipped before starting to count the LIMIT results that are returned.
The USING NAMESPACE clause can be used to define short prefixes for namespaces, which can then be used in abbreviated URIs. Multiple prefixes can be defined, but each declaration must have a unique prefix. The following query shows the use of namespace prefixes:
CONSTRUCT
{Artist} rdf:type {art:Painter};
art:hasPainted {Painting}
FROM
{Artist} rdf:type {art:Artist};
art:hasCreated {Painting} rdf:type {art:Painting}
USING NAMESPACE
rdf = <http://www.w3.org/1999/02/22-rdf-syntax-ns#>,
art = <http://example.org/arts/>The query engine will replace every occurence of rdf: in an abbreviated URI with http://www.w3.org/1999/02/22-rdf-syntax-ns#, and art: with http://example.org/arts/. So art:hasPainted will be resolved to the URI http://example.org/arts/hasPainted.
Four namespaces that are used very frequently have been assigned prefixes by default:
Table 9.1. Default namespaces
| Prefix | Namespace |
|---|---|
| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| rdfs | http://www.w3.org/2000/01/rdf-schema# |
| xsd | http://www.w3.org/2001/XMLSchema# |
| owl | http://www.w3.org/2002/07/owl# |
| sesame | http://www.openrdf.org/schema/sesame# |
These prefixes can be used without declaring them. If either of these prefixes is declared explicitly in a query, this declaration will override the default mapping.
SeRQL contains a number of built-in predicates. These built-ins can be used like any other predicate, as part of a path expression. The difference with normal predicates is that the built-ins act as operators on the underlying rdf graph: they can be used to query for relations between RDF resources that are not explicitly modeled, nor immediately apparant from the RDF Semantics, but which are nevertheless very useful.
Note: in Sesame 2.0 built-in predicates are
only supported on repositories that have a
DirectTypeHierarchyInferencer Sail in the Sail
stack. This inferencer is a stacked Sail that can be deployed on
top of a normal
ForwardChainingRDFSInferencer.
Currently, the following built-in predicates are supported:
{X} sesame:directSubClassOf {Y}This relation holds for every X and Y where:
- X rdfs:subClassOf Y.
- X != Y.
- There is no class Z (Z != Y and Z != X) such that X rdfs:subClassOf Z and Z rdfs:subClassOf Y.
{X} sesame:directSubPropertyOf {Y}This relation holds for every X and Y where:
- X rdfs:subPropertyOf Y.
- X != Y.
- There is no property Z (Z != X and Z != Y) such that X rdfs:subPropertyOf Z and Z rdfs:subPropertyOf Y.
{X} sesame:directType {Y}This relation holds for every X and Y where:
- X rdf:type Y.
- There is no class Z (Z != Y) such that X rdf:type Z and Z rdfs:subClassOf Y.
Note: the above definition takes class/property equivalence through cyclic subClassOf/subPropertyOf relations into account. This means that if A rdfs:subClassOf B, and B rdfs:subClassOf A, it holds that A = B.
The namespace prefix 'sesame' is built-in and does not have to be defined in the query.
SeRQL offers three combinatory operations that can be used to combine sets of query results.
UNION is a combinatory operation the result of which is the set of query answers of both its operands. This allows one to specify alternatives in a query solution.
By default, UNION filters out duplicate answers from its operands. Specifying the ALL keyword ("UNION ALL") disables this filter.
The following example query retrieves the titles of books in the data, where the property used to describe the title can be either from the DC 1.0 or DC 1.1 specification.
Data:
@prefix dc10: <http://purl.org/dc/elements/1.0/> . @prefix dc11: <http://purl.org/dc/elements/1.1/> . _:a dc10:title "The SeRQL Query Language" . _:b dc11:title "The SeRQL Query Language (revision 1.2)" . _:c dc10:title "SeRQL" . _:c dc11:title "SeRQL (updated)" .
Query:
SELECT title
FROM {book} dc10:title {title}
UNION
SELECT title
FROM {book} dc11:title {title}
USING NAMESPACE
dc10 = <http://purl.org/dc/elements/1.0/>,
dc11 = <http://purl.org/dc/elements/1.1/>Result:
| title |
|---|
| "The SeRQL Query Language" |
| "The SeRQL Query Language (revision 1.2)" |
| "SeRQL" |
| "SeRQL (updated)" |
The union operator simply combines the results from both subqueries, matching bindings by their name:
SELECT title, "1.0" AS "version"
FROM {book} dc10:title {title}
UNION
SELECT title
FROM {x} dc11:title {title}
USING NAMESPACE
dc10 = <http://purl.org/dc/elements/1.0/>,
dc11 = <http://purl.org/dc/elements/1.1/>Result:
| title | version |
|---|---|
| "The SeRQL Query Language" | "1.0" |
| "The SeRQL Query Language (revision 1.2)" | |
| "SeRQL" | "1.0" |
| "SeRQL (updated)" |
Since R3.1, the UNION operation can also be applied to path expressions. With this syntax, the first example can be rewritten to a more compact:
SELECT title
FROM
{book} dc10:title {title}
UNION
{book} dc11:title {title}
USING NAMESPACE
dc10 = <http://purl.org/dc/elements/1.0/>,
dc11 = <http://purl.org/dc/elements/1.1/>The INTERSECT operation retrieves query results that occur in both its operands.
The following query only retrieves those album creators for which the name is specified identically in both DC 1.0 and DC 1.1.
Data:
@prefix dc10: <http://purl.org/dc/elements/1.0/> . @prefix dc11: <http://purl.org/dc/elements/1.1/> . _:a dc10:creator "George" . _:a dc10:creator "Ringo" . _:b dc11:creator "George" . _:b dc11:creator "Ringo" . _:c dc10:creator "Paul" . _:c dc11:creator "Paul C." .
Query:
SELECT creator
FROM {album} dc10:creator {creator}
INTERSECT
SELECT creator
FROM {album} dc11:creator {creator}
USING NAMESPACE
dc10 = <http://purl.org/dc/elements/1.0/>,
dc11 = <http://purl.org/dc/elements/1.1/>Result:
| creator |
|---|
| "George" |
| "Ringo" |
The Minus operation returns query results from its first operand which do not occur in the results from its second operand.
The following query returns the titles of all albums of which "Paul" is not a creator.
Data:
@prefix dc10: <http://purl.org/dc/elements/1.0/> . _:a dc10:creator "George" . _:a dc10:title "Sergeant Pepper" . _:b dc10:creator "Paul" . _:b dc10:title "Yellow Submarine" . _:c dc10:creator "Paul" . _:c dc10:creator "Ringo" . _:c dc10:title "Let it Be" .
Query:
SELECT title
FROM {album} dc10:title {title}
MINUS
SELECT title
FROM {album} dc10:title {title};
dc10:creator {creator}
WHERE creator like "Paul"
USING NAMESPACE
dc10 = <http://purl.org/dc/elements/1.0/>,
dc11 = <http://purl.org/dc/elements/1.1/>Result:
| title |
|---|
| "Sergeant Pepper" |
SeRQL has several constructs for nested queries. Nested queries can occur as operands for several boolean operators, which are explained in more detail in the following sections.
SeRQL applies variable scoping for nested queries. This means that when a variable is assigned in the outer query, its value will be carried over to the inner query when that variable is reused there.
The IN operator allows set membership checking where the set is defined by a nested SELECT-query.
The following example query uses the IN operator to retrieve all names of Persons, but only those names that also appear as names of Authors.
@prefix ex: <http://example.org/things#> . _:a rdf:type ex:Person . _:a ex:name "John" . _:b rdf:type ex:Person . _:b ex:name "Ringo" . _:c rdf:type ex:Author . _:c ex:name "John" . _:d rdf:type ex:Author . _:d ex:name "George" .
Query:
SELECT name
FROM {} rdf:type {ex:Person};
ex:name {name}
WHERE name IN ( SELECT n
FROM {} rdf:type {ex:Author};
ex:name {n}
)
USING NAMESPACE
ex = <http://example.org/things#>Result:
| name |
|---|
| "John" |
The ANY and ALL keywords can be used for existential and universal quantification on the right operand of a boolean operator, if this operand is a set, defined by a nested query. The ALL keyword indicates that for every value of the nested query the boolean condition must hold. The ANY keyword indicates that the boolean condition must hold for at least one value of the nested query.
The following query selects the highest value from a set of values using the ALL keyword and a nested query.
Data:
@prefix ex: <http://example.org/things#> . _:a ex:value "10"^^xsd:int . _:b ex:value "11"^^xsd:int . _:c ex:value "12"^^xsd:int . _:d ex:value "13"^^xsd:int . _:e ex:value "14"^^xsd:int .
Query:
SELECT highestValue
FROM {node} ex:value {highestValue}
WHERE highestValue >= ALL ( SELECT value
FROM {} ex:value {value}
)
USING NAMESPACE
ex = <http://example.org/things#>Result:
| highestValue |
|---|
| "14"^^xsd:int |
EXISTS is a unary operator that has a nested SELECT-query as its operand. The operator is an existential quantifier that succeeds when the nested query has at least one result.
In the following example, we use EXIST to determine whether any authors are known that share a name with a person, and if so, to retrieve that person's names and hobbies.
Data:
@prefix ex: <http://example.org/things#> . _:a rdf:type ex:Person . _:a ex:name "John" . _:a ex:hobby "Stamp collecting" . _:b rdf:type ex:Person . _:b ex:name "Ringo" . _:b ex:hobby "Crossword puzzles" . _:c rdf:type ex:Author . _:c ex:name "John" . _:c ex:authorOf "Let it be".
Query:
SELECT name, hobby
FROM {} rdf:type {ex:Person};
ex:name {name};
ex:hobby {hobby}
WHERE EXISTS ( SELECT n
FROM {} rdf:type {ex:Author};
ex:name {n};
ex:authorOf {}
WHERE n = name
)
USING NAMESPACE
ex = <http://example.org/things#>Result:
| name | hobby |
|---|---|
| "John" | "Stamp collecting" |
A new clause, FROM CONTEXT, is introduced in SeRQL 2.0 to allow querying of context. Context can be seen as a grouping mechanism of statements inside a repository, where the group is identified with a context identifier (a URI or a blank node).
A very typical way to use context is tracking provenance of the statements in a repository, that is, which location (on the Web, or on the file system) these statements originate from. For example, consider an application where you add RDF data from different files to a repository, and then one of those files is updated. You would then like to replace the data from that one file in the repository, and to be able to do this you need a way to figure out which statements need to be removed. The context mechanism gives you a way to do that.
By default, a SeRQL query ranges over the total repository. This is known as the default context: we do not specify a context, therefore, the default context is queried. In practice this means that all statements in all contexts in the repository are queried.
In the following example, we have a repository that contains three sets of data. The first set is added without context, the other two each have their own, specific, named context.
Data set 1 (no context):
@prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix g: <http://example.org/contexts/> g:graph1 dc:publisher "Bob" . g:graph1 dc:date "2004-12-06T00:00:00Z"^^xsd:dateTime . g:graph2 dc:publisher "Bob" . g:graph2 dc:date "2005-01-10T00:00:00Z"^^xsd:dateTime .
Data set 2 (context http://example.org/contexts/graph1):
@prefix foaf: <http://xmlns.com/foaf/0.1/> . _:a1 foaf:name "Alice" . _:a1 foaf:mbox <mailto:alice@work.example> . _:b1 foaf:name "Bob" . _:b1 foaf:mbox <mailto:bob@oldcorp.example.org> .
Data set 3 (context http://example.org/contexts/graph2):
@prefix foaf: <http://xmlns.com/foaf/0.1/> . _:a2 foaf:name "Alice" . _:a2 foaf:mbox <mailto:alice@work.example> . _:b2 foaf:name "Bob" . _:b2 foaf:mbox <mailto:bob@newcorp.example.org> .
As you can see, the data in each of the named contexts contains different information about the e-mail address of Bob. Using a 'normal' SeRQL query (that is, without using context information), we can retrieve all e-mail addresses quite easily:
Query:
SELECT DISTINCT name, mbox
FROM {x} foaf:name {name};
foaf:mbox {mbox}
USING NAMESPACE
foaf = <http://xmlns.com/foaf/0.1/>Result:
| name | mbox |
|---|---|
| Alice | mailto:alice@work.example |
| Bob | mailto:bob@oldcorp.example.org |
| Bob | mailto:bob@newcorp.example.org |
However, we can not identify the source of each e-mail address using such a query, because all the statements in the three files are just merged together in a single repository. We can, however, retrieve this information using a context query:
Query:
SELECT DISTINCT source, name, mbox
FROM CONTEXT source
{x} foaf:name {name};
foaf:mbox {mbox}
USING NAMESPACE
foaf = <http://xmlns.com/foaf/0.1/>Result:
| source | name | mbox |
|---|---|---|
| http://example.org/context/graph1 | Alice | mailto:alice@work.example |
| http://example.org/context/graph2 | Alice | mailto:alice@work.example |
| http://example.org/context/graph1 | Bob | mailto:bob@oldcorp.example.org |
| http://example.org/context/graph2 | Bob | mailto:bob@newcorp.example.org |
As you can see, by specifying a variable source
in the FROM CONTEXT clause we can retrieve the named context from
which the information comes.
We can also specify a named context explicitly by using a URI directly, for example if we only want to query source graph2:
Query:
SELECT name, mbox
FROM CONTEXT <http://example.org/context/graph2>
{x} foaf:name {name};
foaf:mbox {mbox}
USING NAMESPACE
foaf = <http://xmlns.com/foaf/0.1/>Result:
| name | mbox |
|---|---|
| Alice | mailto:alice@work.example |
| Bob | mailto:bob@newcorp.example.org |
A SeRQL query may contain any number of FROM CONTEXT clauses and may additionally contain a 'normal' FROM clause as well.
For example, in the following query we combine information from the default context and from the different named contexts to retrieve the most recently published e-mail information:
Query:
SELECT date, source, name, mbox
FROM {source} dc:date {date}
FROM CONTEXT source
{x} foaf:name {name};
foaf:mbox {mbox}
WHERE date >= ALL (SELECT d FROM {} dc:date {d})
USING NAMESPACE
foaf = <http://xmlns.com/foaf/0.1/>,
dc = <http://purl.org/dc/elements/1.1/>Result:
| date | source | name | mbox |
|---|---|---|---|
| "2005-01-10T00:00:00Z"^^xsd:dateTime | http://example.org/context/graph2 | Alice | mailto:alice@work.example |
| "2005-01-10T00:00:00Z"^^xsd:dateTime | http://example.org/context/graph2 | Bob | mailto:bob@newcorp.example.org |
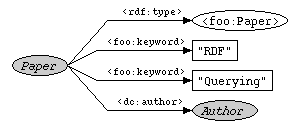
Description: Find all papers that are about "RDF" and about "Querying", and their authors.
SELECT
Author, Paper
FROM
{Paper} rdf:type {foo:Paper};
ex:keyword {"RDF", "Querying"};
dc:author {Author}
USING NAMESPACE
dc = <http://purl.org/dc/elements/1.0/>,
ex = <http://example.org/things#>Depicted as a graph, this query searches through the RDF graph for all subgraphs matching the following template:
Description: Find all artefacts whose English title contains the string "night" and the museum where they are exhibited. The artefact must have been created by someone with first name "Rembrandt". The artefact and museum should both be represented by their titles.
SELECT DISTINCT
label(ArtefactTitle), MuseumName
FROM
{Artefact} arts:created_by {} arts:first_name {"Rembrandt"},
{Artefact} arts:exhibited {} dc:title {MuseumName},
{Artefact} dc:title {ArtefactTitle}
WHERE
isLiteral(ArtefactTitle) AND
lang(ArtefactTitle) = "en" AND
label(ArtefactTitle) LIKE "*night*"
USING NAMESPACE
dc = <http://purl.org/dc/elements/1.0/>,
arts = <http://example.org/arts/>Again, depicted as a subgraph template:
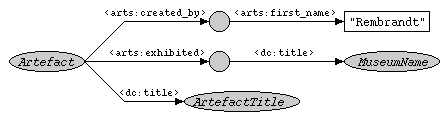
Note that this figure only shows the path expressions from the from clause. The where clause poses additional constraints on the values of the variables which can't be as easily depicted graphically.
Description: Find all siblings of class foo:bar.
SELECT DISTINCT
Sibling
FROM
{Sibling, <foo:bar>} rdfs:subClassOf {ParentClass}Or graphically:
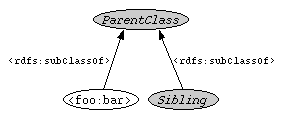
Note that the URI foo:bar is not returned as a result (there is an implicit constraint that doesn't allow Sibling to be equal to values that occur in the same multi-value node).
The following is the BNF grammar of SeRQL, revision 3.0:
ParseUnit ::= Query [NamespaceDeclList]
NamespaceDeclList::= "using" "namespace" NamespaceDecl ("," NamespaceDecl)*
NamespaceDecl ::= <PREFIX_NAME> "=" <URI>
Query ::= TupleQuerySet
| GraphQuerySet
TupleQuerySet ::= TupleQuery [SetOperator TupleQuerySet]
TupleQuery ::= "(" TupleQuerySet ")"
| SelectQuery
GraphQuerySet ::= GraphQuery [SetOperator GraphQuerySet]
GraphQuery ::= "(" GraphQuerySet ")"
| ConstructQuery
SetOperator ::= "union" ["all"]
| "minus"
| "intersect"
SelectQuery ::= "select" ["distinct"|"reduced"] Projection [QueryBody]
Projection ::= "*"
| [ ProjectionElem ("," ProjectionElem)* ]
ProjectionElem ::= ValueExpr ["as" Var]
ConstructQuery ::= "construct" ["distinct"|"reduced"] ConstructClause [QueryBody]
ConstructClause ::= "*"
| PathExprList
QueryBody ::= ("from" ["context" ContextID] PathExprList)+
["where" BooleanExpr]
["order" "by" OrderExprList]
["limit" <POS_INTEGER>]
["offset" <POS_INTEGER>]
ContextID ::= Var
| Uri
| BNode
PathExprList ::= UnionPathExpr ("," UnionPathExpr)*
UnionPathExpr ::= PathExpr ("union" PathExpr)*
PathExpr ::= BasicPathExpr
| OptGraphPattern
| "(" PathExprList ")"
BasicPathExpr ::= Node Edge Node [[";"] PathExprTail]
OptGraphPattern ::= "[" PathExprList ["where" BooleanExpr] "]"
PathExprTail ::= Edge Node [[";"] PathExprTail]
| OptPathExprTail [";" PathExprTail]
OptPathExprTail ::= "[" Edge Node [[";"] PathExprTail] ["where" BooleanExpr] "]"
PathExprCont ::= PathExprBranch
| PathExprTail
PathExprBranch ::= ";" PathExprTail
PathExprTail ::= Edge Node
| "[" Edge Node [PathExprCont] ["where" BooleanExpr] "]"
Edge ::= Var
| Uri
Node ::= "{" [ NodeElem ("," NodeElem)* ] "}"
NodeElem ::= Var
| Value
| ReifiedStat
ReifiedStat ::= "{" [NodeElem] "}" Edge "{" [NodeElem] "}"
OrderExprList ::= OrderExpr ("," OrderExpr)*
OrderExpr ::= ValueExpr ["asc"|"desc"]
BooleanExpr ::= OrExpr
OrExpr ::= AndExpr ["or" BooleanExpr]
AndExpr ::= BooleanElem ["and" AndExpr]
BooleanElem ::= "(" BooleanExpr ")"
| "true"
| "false"
| "not" BooleanElem
| "bound" "(" Var ")"
| "sameTerm" "(" ValueExpr "," ValueExpr ")"
| ValueExpr CompOp ValueExpr
| ValueExpr CompOp ("any"|"all") "(" TupleQuerySet ")"
| ValueExpr "like" <STRING>
| ValueExpr "in" "(" TupleQuerySet ")"
| ValueExpr "in" "(" ArgList ")"
| "exists" "(" TupleQuerySet ")"
| "isResource" "(" Var ")"
| "isURI" "(" Var ")"
| "isBNode" "(" Var ")"
| "isLiteral" "(" Var ")"
| "langMatches" "(" ValueExpr "," ValueExpr ")"
| "regex" "(" ValueExpr "," ValueExpr [ "," ValueExpr ] ")"
CompOp ::= "=" | "!=" | "<" | "<=" | ">" | ">="
ValueExpr ::= Var
| Value
| "datatype" "(" Var ")"
| "lang" "(" Var ")"
| "label" "(" Var ")"
| "namespace" "(" Var ")"
| "localname" "(" Var ")"
| "str" "(" ValueExpr ")"
| FunctionCall
FunctionCall ::= Uri "(" [ArgList] ")"
ArgList ::= ValueExpr ("," ValueExpr)*
Var ::= <NC_NAME>
Value ::= Uri
| BNode
| Literal
Uri ::= <URI>
| <QNAME>
BNode ::= <BNODE>
Literal ::= <STRING>
| <LANG_LITERAL>
| <DT_LITERAL>
| <POS_INTEGER>
| <NEG_INTEGER>
| <DECIMAL>
<URI> ::= "<" (* a legal URI, see http://www.ietf.org/rfc/rfc2396.txt *) ">"
<QNAME> ::= <PREFIX_NAME> ":" <NC_NAME_CHAR>*
<BNODE> ::= "_:" <NC_NAME>
<STRING> ::= (* A quoted character string with escapes *)
<LANG_LITERAL> ::= <STRING> "@" <LIT_LANG>
<DT_LITERAL> ::= <STRING> "^^" (<URI>|<QNAME>)
<POS_INTEGER> ::= "+"? [0-9]+
<NEG_INTEGER> ::= "-" [0-9]+
<DECIMAL> ::= ("+"|"-")? [0-9]* "." [0-9]+
<PREFIX_NAME> ::= <LETTER> <NC_NAME_CHAR>*
| "_" <NC_NAME_CHAR>+
<NC_NAME> ::= (<LETTER>|"_") <NC_NAME_CHAR>*
<NC_NAME_CHAR> ::= (* see http://www.w3.org/TR/REC-xml-names/#NT-NCNameChar *)
<LETTER> ::= (* see http://www.w3.org/TR/REC-xml/#NT-Letter *)Note: all keywords are assumed to be case-insensitive. Whitespace characters between tokens are not significant other than for separating the tokens. Production rules with a head that is surrounded by angular brackets define tokens (aka "terminals").