Introduction
In this homework, we'll be loading some data sets that are output from your Pig analytics into Accumulo, then using a provided web-app to query the data sets.Make sure HDFS, ZooKeeper, and Accumulo are running.
This homework (and all future homeworks) will require heavy internet searching and reading! Use of these tools is best learnt by trial and error, so hit up the Googles.
You're welcome to use this gitrepo that contains several Accumulo exercises in Java.
Goals
- Load data into Accumulo via Python or Java
- Schedule the Accumulo loader via cron
- Implement an AccumuloDataFetcher to retrieve data from Accumulo to be displayed on a Spring web application
Part 1: Load data into Accumulo
Using the previous homework's output, load the tweets, top hashtags, popular users, and reverse index data sets into Accumulo tables called tweets, hashtags, popular_users, and tweet_index.
It is your responsibility to determine the data model for how this data should be stored. What is your row ID? What column families will you have? What are the column qualifiers? How are you storing the values? Then, using Java or Python (with the pyaccumulo Python library), create a simple application to be executed hourly via cron that will scan HDFS for the past hour's Avro tweets and the past hour's analytic output for the top hashtags, popular users, and reverse index. For the purposes of development, you should pull down files and develop locally, then switch to using HDFS files and paths when it is time to deploy your application.
If you're using pyaccumulo, it requires you to use Accumulo's proxy server. After starting the proxy server, you can get the Accumulo connector like so:
# Start the proxy server using a terminal shell
$ accumulo proxy -p /opt/accumulo/proxy/proxy.properties
$ python
Python 2.7.10 (default, Oct 23 2015, 18:05:06)
[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyaccumulo
>>> from pyaccumulo import Accumulo
>>> conn = Accumulo(host="localhost", port=42424, user="root", password="secret")
>>> conn.list_tables()
['accumulo.root', 'trace', 'accumulo.metadata', foo']
Part 2: Schedule your Accumulo ingest
Create a cron job similar to the Pig jobs to execute the Accumulo ingest hourly. Install this application in your analytics directory under your home directory.
Part 3: Implement AccumuloDataFetcher
- Download the accumulo-app starter project. Import it into Eclipse. This app contains a Spring Boot application which is built by Maven. You'll be creating an implementation of DataFetcher to retrieve data from Accumulo, but for now the app simply generates data to be displayed. First, make sure the app works by building and launching the app.
[shook@mb:~]$ wget http://www.csee.umbc.edu/~shadam1/491s16/resources/hw4/accumulo-app.tar.gz .
[shook@mb:~]$ tar -xf accumulo-app.tar.gz
[shook@mb:~]$ cd accumulo-app
[shook@mb:accumulo-app]$ mvn clean package
[shook@mb:accumulo-app]$ java -jar target/accumulo-demo-app-1.0.0.jar
- Navigate to http://localhost:8888 from Firefox in the VM to view the application.
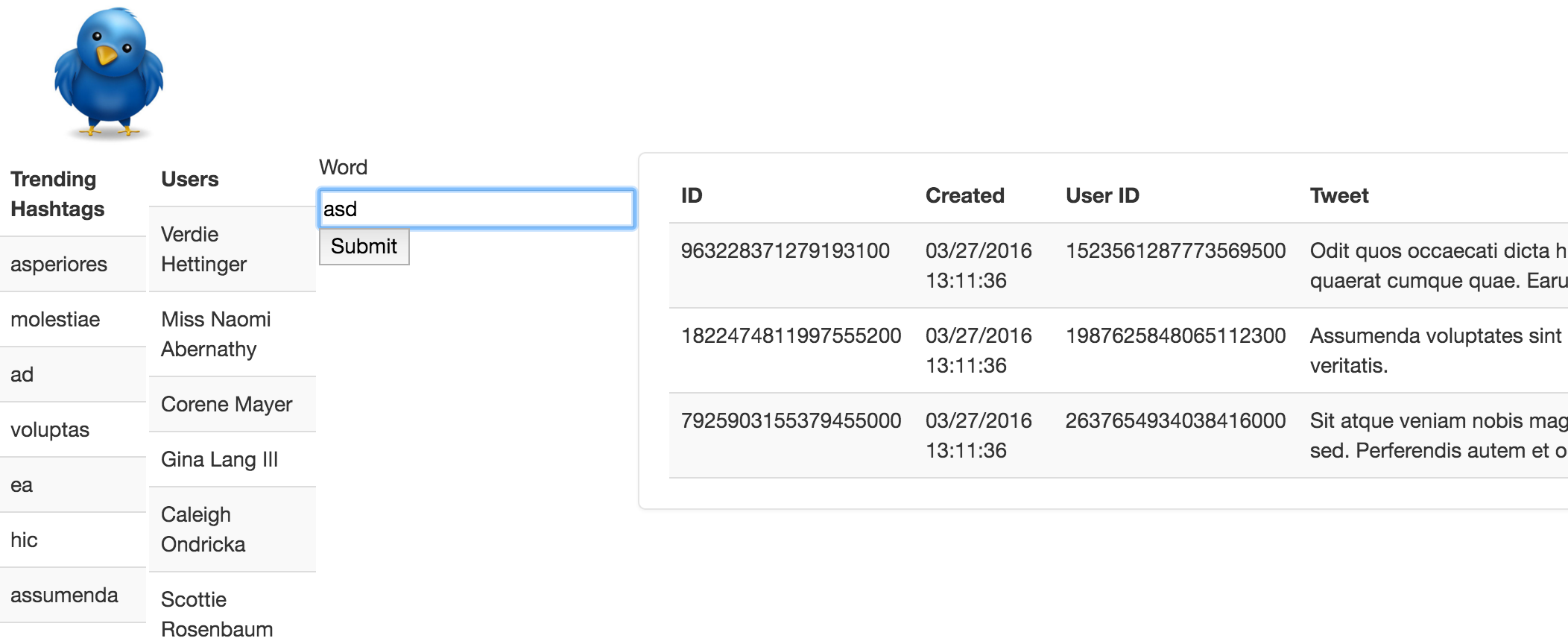
-
Import the Maven project into Eclipse. Under the com.adamjshook.accumulo.demo.app.model package, create a new implementation of DataFetcher called AccumuloDataFetcher that will retrieve tweets containing the given word (using the reverse index table and main tweet table), as well as the top hashtags and popular users. You can rebuild and run your app using the same steps as above -- build with Maven and then execute the jar file. You'll need to change the return vaue of DataFetcher#getDefault to return your AccumuloDataFetcher instead of the GeneratedDataFetcher.
Part 4: Submit your Homework
- Create a "hw4" folder in your git repository. Include the following items in your directory:
- Your data ingestion program
- One log file from the data ingestion program
- A copy of your crontab
- Your entire accumulo-app project, including your Accumulo data fetcher.
- screen shot of your web application with the tweets, top hashtags, and popular users
- Create a README.txt file that contains the following items:
- Instructions on how to execute your project for someone who has no prior knowledge about the project. This should include things like installing your scripts, setting the crontab, viewing the web application, etc. Whatever is needed for another student to check out your homework and get it started (assume all necessary software is installed -- Kafka, HDFS, Avro, your previous homework(s), etc.)
- A list of references, if any, to include Internet links and the names of classmates you worked with.
- Create a tarball of these files and submit only the tarball. Do not include any data sets, generated code, or output! Only source code. For example:
[shadam1@491vm ~]$ cd shadam1-gitrepo
[shadam1@491vm ~]$ git pull
[shadam1@491vm shadam1-gitrepo]$ mkdir hw4
[shadam1@491vm shadam1-gitrepo]$ git add hw4
[shadam1@491vm shadam1-gitrepo]$ cd hw4
[shadam1@491vm hw4]$ # copy files
[shadam1@491vm hw4]$ tar -zcvf hw4.tar.gz *
[shadam1@491vm hw4]$ git add hw4.tar.gz
[shadam1@491vm hw4]$ git commit -m "Homework 4 submission"
[shadam1@491vm hw4]$ git push
What to do if you want to get a 0 on this project:
Any of the following items will cause significant point loss. Any item below with an asterisk (*) will give that submission a 0.
- Missing hw4.tar.gz*
- Submissions in excess of 10MB*
- Missing any of the required files above
- Submissions that do not extract with the command "tar -zxvf hw4.tar.gz"