I ended up using two separate scripts to count bytes and words respectively, since I wanted to count two kinds of bytes: raw bytes between <REUTERS>...</REUTERS> tags, and the number of bytes for the selected terms themselves. Here is a sample of the counts I got:
$ head bwcount2 docid bytes wbytes words 1 3375 2613 205 2 4319 3139 244 3 5148 3550 268 4 8560 6393 444 5 10272 7126 487 6 12206 8075 527 7 13138 8583 551 8 14206 9226 585 9 15067 9663 604 $ tail bwcount2 21569 27358156 17209775 45661 21570 27359258 17210384 45661 21571 27360993 17211617 45663 21572 27365917 17215869 45667 21573 27369178 17218451 45670 21574 27370209 17219033 45671 21575 27372835 17221063 45671 21576 27373826 17221628 45672 21577 27375531 17222862 45673 21578 27377038 17223862 45679And my graph:
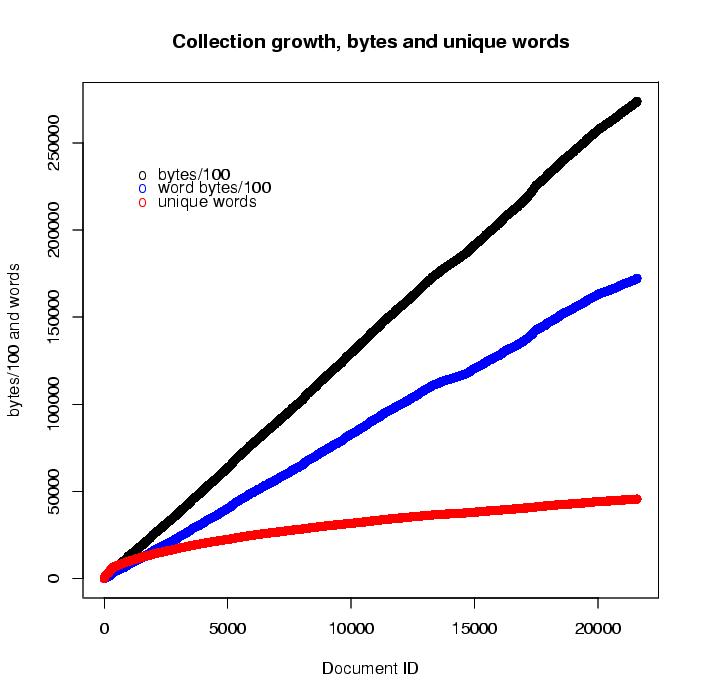
The key thing to notice is that, while the collection size in bytes is linear, no matter which bytes you count (raw or from selected words), the number of unique words grows at a much lower rate, which is in fact O(n^k), 0 < k < 1.
- Each term in the lexicon requires (8 + n) bytes:
- Enough bytes to store the term itself, plus a trailing null,
- Four bytes to store the number of documents containing the term, and
- Four bytes to store a pointer to the term's inverted list.
- Each posting (inverted list entry) requires 12 bytes:
- Four bytes to store a document identifier (sequence number)
- Four bytes to store a count of occurrences in this document.
- Four bytes to store a pointer to the next posting.
$ ./index-size.pl ~/work/corpora/Reuters-21578/reut2-000.sgm Number of unique words: 10101 Size of lexicon (in bytes): 161,086 (158 kb) Size of inverted lists (in bytes): 989,328 (967 kb) (with word offsets) (in bytes): 63,088,328 (61,610 kb) $ ./index-size.pl ~/work/corpora/Reuters-21578/reut2-*.sgm Number of unique words: 45679 Size of lexicon (in bytes): 733,876 (717 kb) Size of inverted lists (in bytes): 20,626,524 (20,144 kb) (with word offsets) (in bytes): 26,480,114,920 (25,859,488 kb)The estimate for including word-offsets in the index is pessimistic; I assume each word occurs once in each document.