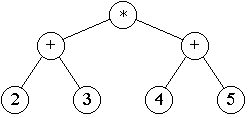
Fig. 1: Expression tree for (2 + 3) * (4 + 5) |
The objectives of this project are 1) to practice coding in C++, 2) to
practice working with binary trees and 3) to gain a glimpse into the
internal workings of a compiler.
A compiler is a program that takes as input a program that is written in a source language and produces as output an equivalent program in a target language. For example, the C compiler you have been using this semester takes programs written in C and converts them into a machine language program. Some computer scientists prefer the name "translator" for a compiler. This is in some sense a better description of the job of a compiler. Although a compiler is special in that it takes another program as input, the compiler itself is nevertheless just a program that handles text.
The job of a compiler is manifold. It must check for syntax errors, give warning messages, resolve references, etc. Assuming that the source program is syntactically correct, the last job of a compiler is to generate code in the target language. This is usually called the "back end" of a compiler. Your task in this project is to implement the back end of a compiler that takes arithmetic expressions as input and generates code in the machine language for a fictitious CPU --- a virtual machine.
Our virtual machine (VM) is quite simple. It has 1K of memory. The CPU has two registers (a.k.a. accumulators) each of which holds a single integer. All arithmetic operations are performed on the data stored in the registers. For example, the ADD instruction adds the numbers in Register A and Register B then stores the result in Register A. Subtraction, multiplication and division are similar. The other instructions supported by this VM are instructions that move data to and from the registers, instructions that print out the contents of a register and an instruction that halts the machine. A complete list of commands can be found in the header file vm.h.
With the exception of the print commands, PRA and PRB, the commands supported by this CPU are fairly typical of a modern CPU. Of course, a full-blown CPU would have instructions for branching, indirect addressing modes and many more registers. However, compiling code for arithmetic expressions on a "real" CPU is no easier and no harder than what you have to do in this project.
For this project, you will implement two member functions for the expression tree class ETree. These functions generate the machine code for the arithmetic expression stored in the expression tree. These member functions are declared as follows in the header file etree.h.
The function compile() is a public member function. The function rec_compile() is private and will end up doing most of the work. The algorithm you should implement is recursive (surprise!). The idea is that you would perform what is essentially a post-order walk through the expression tree and generate code at each node. The code that you generate is placed in the FIFO queue, Q.
|
Fig. 1: Expression tree for (2 + 3) * (4 + 5) |
It is important at this point to establish some sort of convention about where the result of the code is stored. Let us say arbitrarily that the result of the code generated by rec_compile() is stored in Register B. Now consider the expression (2 + 3) * (4 + 5). The expression tree for this expression is shown in Figure 1. Suppose that we have finished generating the code for (2+3) and by convention, the result the addition is stored in Register B. The next step is to generate code for the right subtree, namely (4 + 5). In order to do this, we must load 4 and 5 into Registers A and B which would overwrite the results from the previous addition. Thus, we must somehow save Register B after performing the addition (2+3). We could for example store Register B in memory location 0. After performing the addition for (4+5) with the result in Register B, we can then copy memory location 0 into Register A and perform the final multiplication. The code generated by this scheme might be the following:
The problem with this code is that we did not recursively apply our convention to every single node in the tree. If we followed the algorithm, we would load the constant 2 into Register B instead of Register A, because the convention says to generate code that puts the value into Register B. We would then save Register B in location 0, then copy location 0 into Register A. This generates "stupid" code, but it can be done mechanically (and you now understand why there is such a thing as an optimizing compiler). Thus, following our algorithm, the first part of the code would be:
Can we continue with this scheme? We have a problem. To generate code for (4+5) in our mechanical way, we would load 4 into Register B and save it in memory location 0. But 0 is where we just put the result of (2+3)! That location must remain untouched until we are ready to multiply (2+3) with (4+5). That is why we pass a second parameter low_mem to the function rec_compile(). This integer parameter is the location of the lowest memory address that the code generated by this call to rec_compile() is allowed to modify. In this example, we don't want successive calls to rec_compile() to change memory location 0, so we would pass to rec_compile() a value of 1 for the low_mem parameter. Thus, instead of saving Register B in memory location 0, we would save Register B in memory location 1. Therefore, the code we generate for the expression (2+3) * (4+5) would end with:
For complex expressions the parameter low_mem can get bigger and bigger. For example,. when we generate code for the expression (2 + 3) * (4 + 5 * (7 - 2)), the value of low_mem would be 3 when we generate the code for the subexpression (7-2).
You must use C++ for this project. You do not need to write any code to generate the expression tree. This is already done for you, as was shown in class. All the files you need are in the directory ~chang/pub/cs202/proj5/. You should use the files in this directory and not files with the same names that you may have downloaded off the web pages. (The files in this directory contain some minor fixes.) Unless you are doing the extra credit project, you should not modify the files that you copy from this directory.
In addition to the two compilation functions mentioned above, you must also implement the member functions of the class ListItem defined in codeitem.h. Recall that the ListItem class defines the data objects used by the Queue class.
A sample main program is provided which demonstrates the intended use of the compile() function and the Queue class. The main program also calls the vm_emulate() function which is a small program that runs the machine code you generated.
Note: this project is straightforward. Start now and you won't have trouble with the deadline. Unless unforeseen events shut down the campus (e.g., 3 feet of snow in May), there will not be an extension on the project deadline. (Yes, I know May 6th is not the last day of classes.)
You should turn in the following items:
You should only attempt the extra credit project if you have completed the regular project.
For extra credit, you must accomplish both of the following tasks. First, you must implement what is called a peephole optimizer on the code that you generate. Second, you must expand the source language to include variables, assignments and multi-line programs. Extra credit is all or nothing --- i.e., you either get 25 points or 0 points for extra credit.
A peephole optimizer looks at a small section of the machine code generated by a compiler to see if that sequence of instructions can be improved. For example, in the code we generated above for the expression (2+3)*(4+5), we have the following sequence of 4 instructions right after we perform the addition for (2+3):
We can replace the two commands TAB and STB with a single command that stores the value in Register A into memory location 0 directly. It is fairly obvious that the value in Register B is never used again since the LDBC instruction overwrites whatever was stored in Register B. Thus, we would save 1 instruction. This type of redundant code can be found by looking at every sequence of 3 instructions. Can you think of any other pattern of redundant code generated by our algorithm? Can you improve the algorithm itself? (Please describe the improvements that you have implemented in the README file that you submit.)
The second task you must accomplish is to expand the source language to include 10 variables called x0, x1, ..., x9. Furthermore, the statements in our source language can now be of two types: assignments and print statements. For example, your compiler must be able to generate code for:
(Executing the code should print out 88.) To make these changes, you have to modify both the tokenizer and the parser to handle variables, assignments and the symbol PRINT. You are also allowed to modify any file as you see fit. (Again, please document the changes in the README file.)
If you do the extra credit project, you should submit every file that is required to compile your program (i.e., let's just assume that you've modified every .C and .h file). Furthermore, when you turn in your project, use the project name proj5-extra (instead of proj5) in the submit command. Finally, the deadline for the extra credit project is the same as the deadline for the regular project.