Due at the start of class on February 14
Install scikit-learn for Python. If you are a Windows user, download the latext WinPython distribution from here. Go through the installation process, and find "IPython QT Console" and run it. That will give you a Python command prompt with all of the packages you need. If you are a Linux user, this Stack Overflow question and answer shows you how to install it.
Once you've got Python and scikit-learn running, execute the following code and submit the output.
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import numpy as np
digits = datasets.load_digits()
for n in range(1, 501, 50):
clf = KNeighborsClassifier(n_neighbors = n)
scores = cross_val_score(clf, digits.data, digits.target, cv = 10)
print('k = %d, acc = %.2f' % (n, np.mean(scores)))
You'll notice that the cross-validated accuracy scores are
decreasing. Explain why that is happening in a sentence or two.
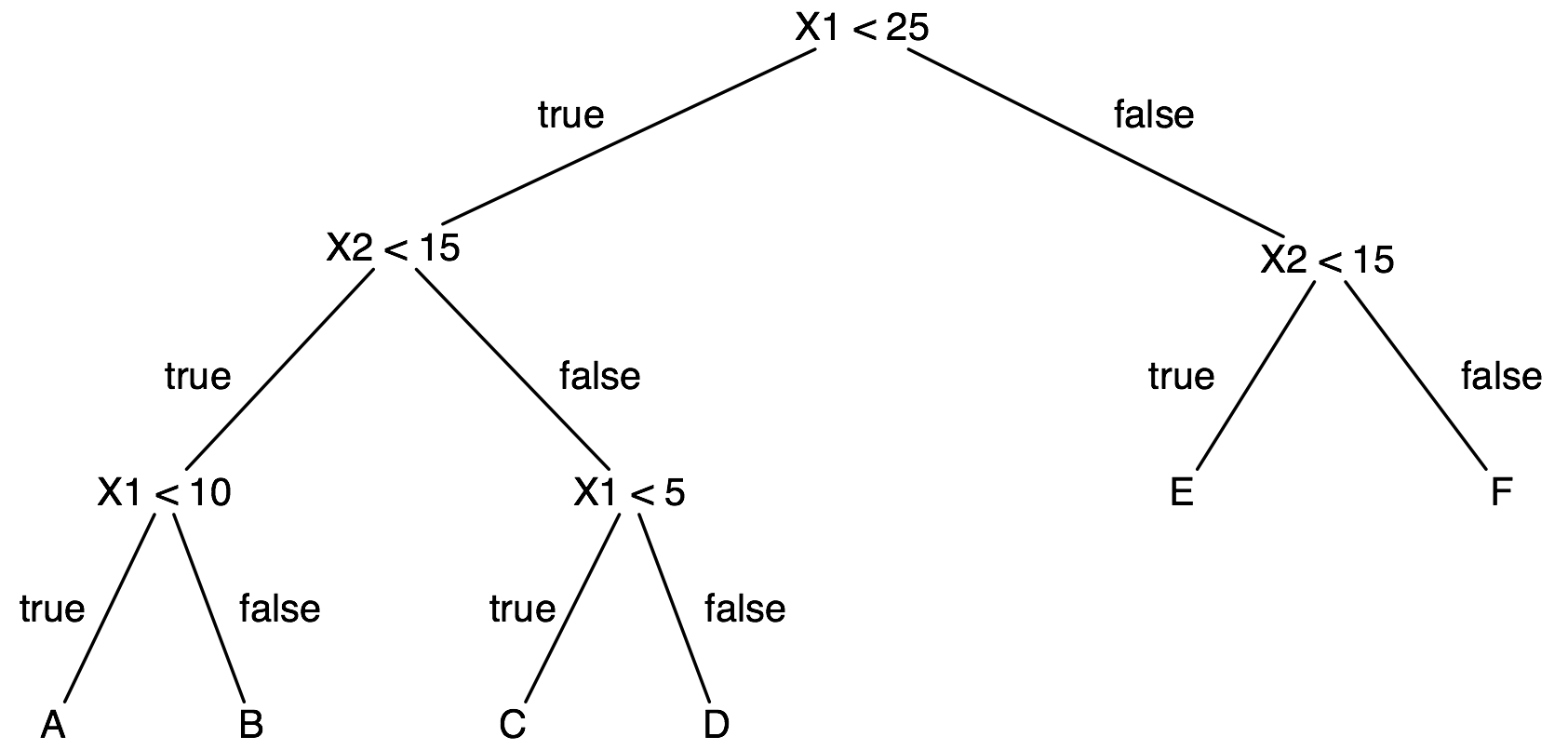
Consider the following decision tree:
Draw the decision boundaries defined by this tree. Each leaf is labeled with a letter. Write this letter in the corresponding region of instance space.