| UMBC | CMSC 391 -- Programming Microcontrollers |
Quote
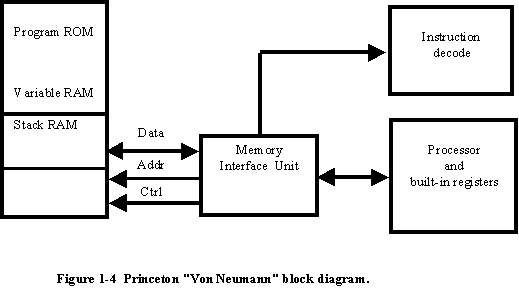
Princeton's response was a computer that had common memory for storing the control program as well as variables and other data structures. It was best known by the chief scientist's name "Von Neumann" (Fig 1-4).
The memory interface unit is responsible for arbitrating access to the memory space between reading instructions (based upon the current program counter) and passing data back and forth with the processor and its internal registers.
It might at first seem that the memory interface unit is a bottleneck between the processor and the variable/RAM space (especially with the requirement for fetching instructions at the same time); however, in many Princeton architected processors, this is not the case because the time required to execute a given instruction can be used to fetch the next instruction (this is known as pre-fetching and is a feature on many Princeton architected processors.
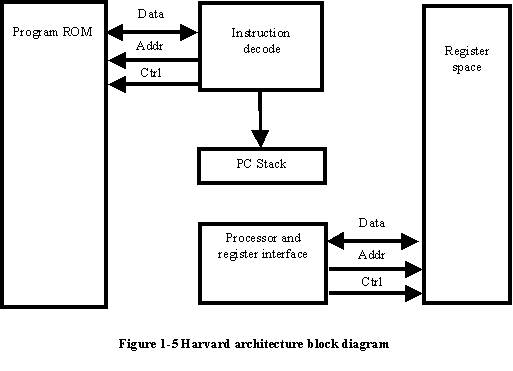
In contrast, Harvard's response was a design that used separate memory banks for program store, the processor stack, and variable RAM. (See Fig. 1-5.)
The Princeton architecture won the competition because it was better suited for the technology of the time. Using one memory was preferable because of the unreliability of current electronics (this was before transistors were in widespread use). A single memory interface would have fewer things that could go wrong.
The Harvard architecture was largely ignored until the late 1970s when microcontroller manufacturers realized that the architecture had advantages for the devices they were currently designing.
What are the advantages of the two architectures?
The Von Neumann architecture's largest advantage is that it simplifies the microcontroller chip design because only one memory is accessed. For microcontrollers, its biggest asset is that the contents of RAM (random-access memory) can be used for both variable (data) storage as well as program instruction storage. An advantage for some applications is the program counter stack contents that are available for access by the program. This allows greater flexibility in developing software, primarily in the areas of real-time operating systems.
The Harvard architecture executes instructions in fewer instruction cycles that the Von Neumann architecture. This is because a much greater amount of instruction parallelism is possible in the Harvard architecture. Parallelism means that fetches for the next instruction can take place during the execution of the current instruction, without having to either wait for a "dead" cycle of the instruction's execution or stop the processor's operation while the next instruction is being fetched.
Unquote