D2R Server is a tool for publishing relational databases on the Semantic Web.
It enables RDF and HTML browsers to navigate the content of the database,
and allows applications to query the database using the SPARQL query language.
Download D2R Server
v0.7 (alpha), released 2009-08-10Live Demo
Web-based Systems Group databaseNews
- 2009-08-10: Version 0.7 released. This version provides several bugfixes, better dump performance, several new features as well as new optimizations that must be enabled using the new --fast switch.
- 2009-02-19: Version 0.6 released. This version introduces serving of vocabulary data and includes D2RQ 0.6, which provides significantly improved performance and memory usage, new features and several bugfixes.
- 2007-11-03: Version 0.4 released. This version can be run as a J2EE web application inside existing servlet containers and fixes several bugs.
- 2007-02-13: Version 0.3.2 released, featuring more configurability, easy installation as a Windows service, and many small improvements and bugfixes.
- 2007-01-22: dbpedia.org uses D2R Server to publish structured data extracted from Wikipedia.
- 2006-12-20: Gene Ontology servers: Chris Mungall (Berkeley Drosophila Genome Project) has set up D2R Servers for Gene Ontology annotations and gene expression in fruitfly embryogenesis.
- 2006-11-02: DBLP Bibliography server: We have published the DBLP Bibliography Database on the Semantic Web using D2R Server.
Contents
- About D2R Server
- Quick start
- Customizing the database mapping
- Serving vocabulary classes and properties
- Server configuration
- Optimizing performance
- Running D2R Server as a service on Windows
- Running D2R Server in an existing Servlet Container
- Creating RDF dumps
- Pre-built mapping files
- Support and Feedback
- Source code and development
- Public servers
- Related projects
About D2R Server
D2R Server is a tool for publishing the content of relational databases on the Semantic Web, a global information space consisting of linked data.
Data on the Semantic Web is modelled and represented in RDF. D2R Server uses a customizable D2RQ mapping to map database content into this format, and allows the RDF data to be browsed and searched – the two main access paradigms to the Semantic Web.
D2R Server's Linked Data interface makes RDF descriptions of individual resources available over the HTTP protocol. An RDF description can be retrieved simply by accessing the resource's URI over the Web. Using a Semantic Web browser like Tabulator (slides) or Disco, you can follow links from one resource to the next, surfing the Web of Data.
The SPARQL interface enables applications to search and query the database using the SPARQL query language over the SPARQL protocol.
A traditional HTML interface offers access to the familiar Web browsers.
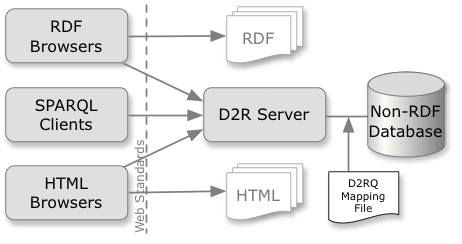
Requests from the Web are rewritten into SQL queries via the mapping. This on-the-fly translation allows publishing of RDF from large live databases and eliminates the need for replicating the data into a dedicated RDF triple store.
Read more about the interfaces offered by D2R Server, including example HTTP requests and responses, in the Technical Note Publishing Databases on the Semantic Web.
Quick start
You need:
- Java 1.4 or newer on the path (check with java -version if you're not sure),
- A supported database. D2R Server works with Oracle, MySQL, PostgreSQL, Microsoft SQL Server, and any SQL-92 compatible database. Microsoft Access can be used with some restrictions. More information is available in the D2RQ manual.
- a modern browser like Firefox, Opera or Safari for using D2R Server's AJAX SPARQL Explorer. Internet Explorer can only browse the HTML pages, but not use the SPARQL Explorer.
- Optionally, a J2EE servlet container as a deployment target. D2R Server can be run either as a stand-alone web server or inside an existing servlet container.
What to do:
Download and extract the archive into a suitable location.
Download a JDBC driver from your database vendor. Place the driver's JAR file into D2R Server's /lib directory. A list of JDBC drivers from different vendors is maintained by Sun. Also take note of the driver class name (e.g. org.postgresql.Driver for PostgreSQL or oracle.jdbc.driver.OracleDriver for Oracle) and JDBC URL pattern (e.g. jdbc:mysql://servername/database for MySQL) from the driver's documentation. Drivers for MySQL and PostgreSQL are already included with D2R Server.
Generate a mapping file for your database schema. Change into the D2R Server directory and run:
generate-mapping -o mapping.n3 -d driver.class.name -u db-user -p db-password jdbc:url:...mapping.n3 is the name for the new mapping file. -d can be skipped for MySQL.
Start the server:
d2r-server mapping.n3
-
Test the Server: Open http://localhost:2020/ in a web browser.
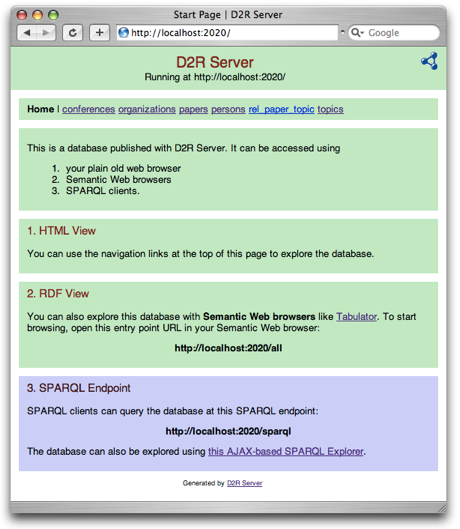
You can browse the database content or use the SPARQL Explorer to execute queries and display results in a number of formats.
To test the data in an RDF browser, open any resource URI in Tabulator. You may have to tweak your Firefox settings first – see the Tabulator help.
Customizing the database mapping
D2R Server uses the D2RQ Mapping Language to map the content of a relational database to RDF. A D2RQ mapping specifies how resources are identified and which properties are used to describe the resources.
The generate-mapping script automatically generates a D2RQ mapping from the table structure of a database. The tool generates a new RDF vocabulary for each database, using table names as class names and column names as property names. Semantic Web client applications will understand more of your data if you customize the mapping and replace the auto-generated terms with terms from well-known and publicly accessible RDF vocabularies.
The mapping file can be edited with any text editor. Its syntax is described in the D2RQ Manual. D2R Server will automatically detect changes to the mapping file and reload appropriately when you hit the browser's refresh button.
Note: The HTML and RDF browser interfaces only work for URI patterns that are relative and do not contain the hash (#) character. For example, a URI pattern such as entries/@@mytable.id@@ is browsable, but http://example.com/entries#@@mytable.id@@ is not. The mapping generator only creates browsable patterns. Non-browsable patterns still work in the SPARQL interface and in RDF dumps.
Serving vocabulary classes and properties
A D2R deployment often requires the introduction of custom classes and properties. In the spirit of Linked Data, vocabulary data should be dereferencable by clients. D2RQ infers types of classes and properties, and allows the user to provide labels, comments and additional properties.
D2R Server automatically serves data for vocabularies placed under http://baseURI/vocab/resource/, with RDF and HTML representations located at http://baseURI/vocab/data/ and http://baseURI/vocab/page/, respectively. The following mapping illustrates the intended usage:
@prefix vocabClass: <http://localhost:2020/vocab/resource/class/> . @prefix vocabProperty: <http://localhost:2020/vocab/resource/property/> . map:offer a d2rq:ClassMap; d2rq:classDefinitionLabel "Offer"@en; d2rq:classDefinitionComment "This is an offer"@en; d2rq:class vocabClass:Offer; .
When dereferenced, http://localhost:2020/vocab/resource/class/Offer will return the specified label and comment as well as the automatically inferred type rdfs:Class. Note that the prefixes are bound to absolute URIs because relative URIs would be based under http://localhost:2020/resource/.
D2RQ offers several constructs to provide data for classes and properties. Please refer to the D2RQ Language Specification for more details.
Server configuration
The server can be configured by adding a configuration block to the mapping file:
@prefix d2r: <http://sites.wiwiss.fu-berlin.de/suhl/bizer/d2r-server/config.rdf#> .
<> a d2r:Server;
rdfs:label "D2R Server";
d2r:baseURI <http://localhost:2020/>;
d2r:port 2020;
d2r:documentMetadata [
rdfs:comment "This comment is custom document metadata.";
];
d2r:vocabularyIncludeInstances true;
.
The rdfs:label is the server name displayed throughout the HTML interface.
The d2r:baseURI and d2r:port must be changed to make the D2R Server accessible to remote machines.
All statements inside the d2r:documentMetadata block will be added as document metadata to all RDF documents.
The d2r:vocabularyIncludeInstances setting controls whether the RDF and HTML representations of vocabulary classes and properties will also list related instances (defaults to true). As an alternative to disabling the serving of vocabulary instances, d2rq:resultSizeLimit may be used to limit the amount of returned data. Vocabulary serving is a feature of D2RQ and may be controlled using the d2rq:serveVocabulary property.
The d2r:autoReloadMapping setting specifies whether changes to the mapping file should be detected automatically (defaults to true). This feature has performance implications, so this value should be set to false for high-traffic production systems or when running benchmarks.
All parts are optional.
With large databases, some queries will produce too many results. Adding a d2rq:resultSizeLimit to the d2rq:Database section of the mapping file will add a LIMIT clause to all generated statements.
d2rq:resultSizeLimit 500;
Not that this effectively “cripples” the server and can cause somewhat unpredictable results. We still recommend it until we can offer a better solution.
Optimizing performance
Here are some simple hints to improve D2R's performance:
- Define primary keys whenever you can and create indexes where applicable (e.g. on foreign keys) – besides optimizing database performance, these will be picked up and used by various optimizations within D2RQ.
- Use the latest optimizations by launching with --fast (or activate d2rq:useAllOptimizations).
- Provide hint properties.
- Indicate directions in d2rq:joins to enable join optimizations.
- Give D2R adequate heap space by means of Java's -Xmx parameter in d2r-server or d2r-server.bat (default: -Xmx256M).
- Set d2rq:autoReloadMapping to false where it is not required.
- Databases often ship with development configurations that are designed for a small footprint rather than performance. For instance, some good pointers for optimizing MySQL can be found here.
Running D2R Server as a service on Windows
To run D2R Server as a service on Windows, use the install-service script:
install-service servicename mapping.n3
The service can be started from the Services panel in the management console. The service will log all output including startup errors to the files stdout.log and stderr.log.
To uninstall the service, use uninstall-service. You have to uninstall and re-install the service when upgrading to a later version of D2R Server.
Running D2R Server in an existing Servlet Container
By default, D2R Server is a stand-alone server application that includes its own web server. But D2R Server can also be run as a J2EE web application inside an existing servlet container, such as Tomcat:
- Make sure that your mapping file includes a configuration block, as described in the server configuration section. Set the port number to that of the servlet container, and set the base URI to something like http://servername/webappname/.
- Change the configFile param in /webapp/WEB-INF/web.xml to the name of your configuration file. For deployment, we reommend placing the mapping file into the /webapp/WEB-INF/ directory.
- In D2R Server's main directory, Run ant war. This creates the d2r-server.war file. You need Apache Ant for this step.
- Optionally, if you want a different name for your web application, rename the file to webappname.war
- Deploy the war file into your servlet container, e.g. by copying it into Tomcat's webapps directory.
Creating RDF dumps
Sometimes it is useful to create an RDF dump of the entire database. The dump-rdf script can be used for this purpose. See the D2RQ manual for details.
Pre-built mapping files
We collect mapping files for popular database-driven applications.
Have another one? Please share it.
Support and feedback
You can contact us on the D2RQ mailing list at d2rq-map-devel@lists.sourceforge.net.
Source code and development
D2R Server combines the D2RQ API, the Joseki SPARQL Server and the Jetty webserver.
D2R Server is hosted by SourceForge.net as part of the D2RQ project. The latest source code is available from the project's CVS repository and can be browsed online.
Public servers
- Gene Ontology annotations (Chris Mungall, more information)
- Annotated images of gene expression in fruitfly embryogenesis (Chris Mungall, more information)
- DBLP Bibliography Database on the Semantic Web
- Web-based Systems Group @ Freie UniversitŠt Berlin – Information about staff, projects and publications
- Roller blog server demo (Henry Story, more information)
- D2R Server Live Demo publishing an example conference database
Related projects
- SquirrelRDF provides SPARQL access to relational databases and LDAP directories.
- OpenLink Virtuoso provides flexible RDF access to a wide range of data sources, including relational data.
- METAmorphoses publishes RDF generated from relational databases on the Web.
- List of projects and publications about database-to-RDF mapping at the ESW Wiki.
- Other open source projects of our group