 UMBC CSEE Professor Tim Oates recently received a grant from NSF, “Truly Distributed Deep Learning: Representation and Computation”, to develop new architectures for deep learning systems that are distributed, allowing greater scale and control over data management and privacy.
UMBC CSEE Professor Tim Oates recently received a grant from NSF, “Truly Distributed Deep Learning: Representation and Computation”, to develop new architectures for deep learning systems that are distributed, allowing greater scale and control over data management and privacy.
In many scientific domains, from healthcare to astronomy, our ability to gather data far outstrips our ability to analyze it. Most data analysis algorithms require all of the data to be available at one central location, but that is not always possible due to either the sheer size of the data or, as in healthcare, privacy concerns. The goal of this project is to develop data analysis algorithms that can be run on distributed datasets, where different physical locations contain a subset of the data. Applications include medical diagnostic tools that are more accurate because they are based on significantly larger datasets than is currently possible, and crowdsourcing data analysis tasks by allowing anyone with some spare compute capacity to participate in a global-scale computation.
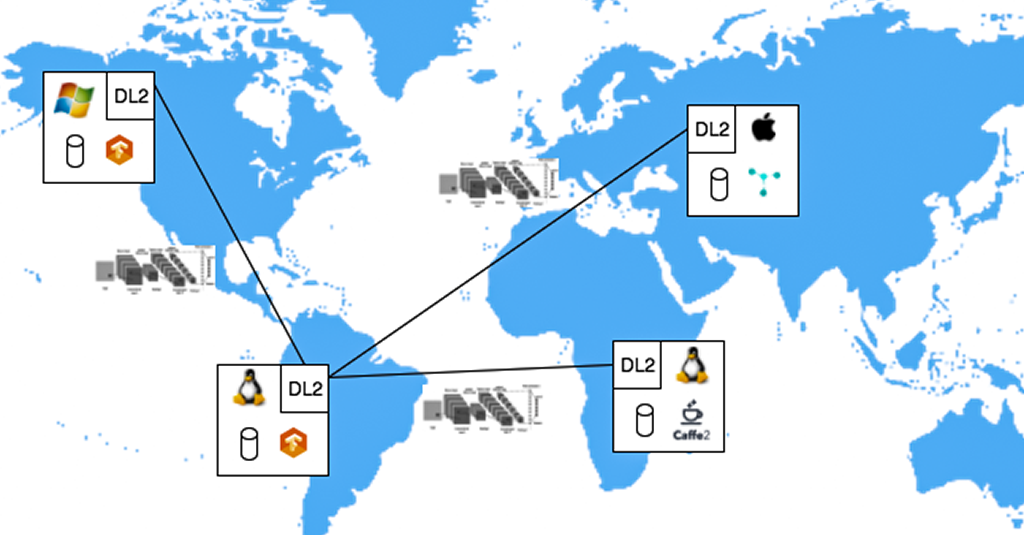
The project has two aims. The first is the design and implement an ontologically backed Deep Learning Description Language (DL2) for representing all phases on deep learning, including model structure, hyperparameters, and training methods. DL2 will serve as an interlingua between deep learning frameworks, regardless of the hardware architecture on which they run, to support model sharing, primarily in service of truly distributed learning. The ontological underpinnings of DL2 will support, among other things, explicit reasoning about framework compatibility when sharing models; a “model zoo” that is open to all, not just users of a specific framework; and the ability to formulate semantic queries against model libraries to, for example, find similar models.
The second aim is to design, implement, and thoroughly evaluate a number of truly distributed algorithms for deep learning that leverage DL2 for model sharing. Existing approaches to distributed machine learning rely on distributed algorithms that exchange shallow, compact models that are orders of magnitude smaller than modern deep networks, leading to interesting challenges in adapting distributed averaging to deep learning.