<- previous index next ->
This lecture covers the software interface to the computer
architecture. Note that Unix was around many years before
MS DOS and MS Windows, thus similar capability.
Just a little history from the current man page for gcc.
Note: The term "text" and "text segment" are instructions,
executable code.
From man gcc then /segment
-fwritable-strings
Store string constants in the writable data segment and don't
uniquize them. This is for compatibility with old programs which
assume they can write into string constants.
Writing into string constants is a very bad idea; ''constants''
should be constant.
This option is deprecated.
-fconserve-space
Put uninitialized or runtime-initialized global variables into the
common segment, as C does. This saves space in the executable at
the cost of not diagnosing duplicate definitions. If you compile
with this flag and your program mysteriously crashes after "main()"
has completed, you may have an object that is being destroyed twice
because two definitions were merged.
This option is no longer useful on most targets, now that support
has been added for putting variables into BSS without making them
common.
-msep-data
Generate code that allows the data segment to be located in a dif-
ferent area of memory from the text segment. This allows for
execute in place in an environment without virtual memory manage-
ment. This option implies -fPIC.
-mno-sep-data
Generate code that assumes that the data segment follows the text
segment. This is the default.
in same page, better more likely bad
=============== =============== page boundary
+-------------+ +-------------+
| | buffer | | buffer
| code | over run | data | over run
+-------------+ backward +-------------+ forward
| | into | | into
| data | code | code | code
+-------------+ +-------------+
=============== =============== page boundary
Best if code and data not in same page
The page can then be "read-only" or "execute-only"
-mid-shared-library
Generate code that supports shared libraries via the library ID
method. This allows for execute in place and shared libraries in
an environment without virtual memory management. This option
implies -fPIC.
We will see -fPIC is used directly, below.
Now, consider an operating system that allocated physical pages,
via the TLB:
1) that contained only code - set to execute only or read only
2) that contained constant data - set to read only
3) that contained variables, including stack and heap - writable
Any virus or Trojan that tried to overwrite code would be trapped.
No possible "buffer overrun" or other malicious action could occur.
But, today's operating systems may put both code and variables into
the same physical page. This is most common with .so and .dll files.
Thus, the hacker can cause data to be written over your programs
instructions. What is written are the harmful instructions to
erase your hard drive or do other damage. This is a legacy OS code
problem that dates back to small core memory systems. There does not
seem to be a willingness to fix this, currently, dangerous situation.
e.g. How could displaying a .jpg image allow a virus?
Oh! Because some idiot believed the size in the header
and kept reading data that over wrote instructions.
Double Yuk! 1) Not checking size 2) code and data in same segment
Thus, they helped create cybercrime and thus cyberdefense.
As a part of MS Windows is DOS, now often called a command window
or command prompt. Just typing "help" list most available commands.
Different names for similar file types and commands are:
Unix, Linux, MacOSX MS Windows description
.o .obj relocatable object file
<no extension> .exe executable file
.so .dll shared object, dynamic link load
.a .lib library of relocatable object files
statically linked inside executable
.c .c "C" source file
gcc -c xxx.c cl /C xxx.c just make relocatable object file
ar -crv libxxxx.a cl /LD xxxx.lib build a library file of many
relocatable object files
-lxxxx xxxx.lib use library file
An example of building a self contained executable from a .a library
and an executable that needs a shared object .so available:
A self contained executable can be distributed as a single file for
a specific operating system.
An executable file that links to .so or .dll files will be much
smaller and only one copy of the .so or .dll file needs to be
in RAM, even when many executable programs need them.
The .so or .dll files must be distributed with the executable file.
First, the main programs and the four little C library functions that
print their name in execution:
/* ax.c for libax.a test */
#include <stdio.h>
int main()
{
printf("In ax main \n");
abc();
xyz();
return 0;
}
/* abc.c for libax.a test */
#include <stdio.h>
void abc()
{ printf("In abc \n"); }
/* xyz.c for libax.a test */
#include <stdio.h>
void xyz()
{ printf("In xyz \n"); }
/* ab.c for libab.so test */
#include <stdio.h>
int main()
{
printf("In ab main \n");
aaa();
bbb();
return 0;
}
/* aaa.c for libab.so test */
#include <stdio.h>
void aaa()
{ printf("In aaa \n"); }
/* bbb.c for libab.so test */
#include <stdio.h>
void bbb()
{ printf("In bbb \n"); }
Then, the Makefile_so
# Makefile_so demo ar and ld and shared library .so
all: ax ab
ax : ax.c abc.c xyz.c
gcc -c abc.c # compile for library
gcc -c xyz.c
ar crv libax.a abc.o xyz.o # build library
ranlib libax.a
rm -f *.o
gcc -o ax ax.c -L. -lax # use library libax.a
./ax # execute
ab : ab.c aaa.c bbb.c
gcc -c -fpic -shared aaa.c # compile for library
gcc -c -fpic -shared bbb.c
ld -o libab.so -shared aaa.o bbb.o -lm -lc
rm -f *.o
gcc -o ab ab.c -L. -lab # use links to library
./ab # need LD_LIBRARY_PATH to include this directory
# many users have "." meaning "here" "this directory" in path
abg : ab.c aaa.c bbb.c # uses /usr/local/lib needs root priv
gcc -c -fpic -shared aaa.c
gcc -c -fpic -shared bbb.c
ld -o libab.so -shared aaa.o bbb.o -lm -lc
rm -f *.o
cp libab.so /usr/local/lib # install for all users
rm -f libab.so
ldconfig
gcc -o abg ab.c -lab # any user can get libab.so
./abg # any user has access to libab.so
clean:
rm -f ax
rm -f ab
rm *.a
rm *.so
To see what is inside, gcc -S -g3 ax.c
ax.s
Here are some examples of addressing as seen in assembly code
and .o or .obj files. Then in executable a.out or .exe files
as seen through the debugger. The "relocatable" addresses are
converted to "virtual" addresses then during execution converted
to "physical" or RAM addresses. Coming soon to a WEB page near you.
To get memory map, yuk, output, add -Ml,-M to gcc -o ... command
ax.map
Remember, those huge addresses are virtual addresses.
Your program may run with much smaller physical memory.
Information that might help with Project part3
Some are ready to implement part3 of the project.
Part3 description.
You may use a complete behavioral solution, just code the
hit/miss process you did by hand in Homework 9, 2a. This may be
based on the code below.
Put the caches inside the instruction memory, part3a, and
and data memory, part3b, components (entity and architecture).
(you will need to pass a few extra signals in and out)
Use the existing shared memory data as the main memory.
Make a miss on the instruction cache cause a three cycle stall.
Make a miss on the data cache cause a three cycle stall.
Previous stalls from part2b must still work.
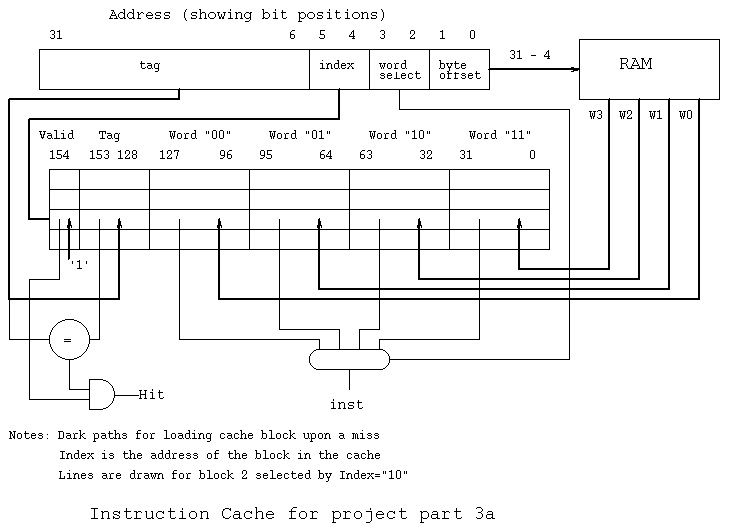
Both instruction cache and data cache hold 16 words
organized as four blocks of four words. Remember vhdl
memory is addressed by word address, the MIPS/SGI memory
is addressed by byte address and a cache is addressed by
block number.
The cache schematic for the instruction cache was handed out
in class and shown in. icache.jpg
The cache may be implemented using behavioral VHDL, basically
writing sequential code in VHDL or by connecting hardware.
 Possible behavioral, not required, VHDL to set up the start of a cache:
(no partial credit for just putting this in your cache.)
-- add in or out signals to entity instruction_memory as needed
-- for example, 'clk' 'clear' 'miss'
architecture behavior of instruction_memory is
subtype block_type is std_logic_vector(154 downto 0);
type cache_type is array (0 to 3) of block_type;
signal cache : cache_type := (others=>(others=>'0'));
-- now we have a cache memory initialized to zero
begin -- behavior
inst_mem:
process ... -- whatever, does not have to be just 'addr'
variable quad_word_address : natural; -- for memory fetch
variable cblock : block_type;-- the shaded block in the cache
variable index : natural; -- index into cache to get a block
variable word : natural; -- select a word
variable my_line : line; -- for debug printout
variable W0 : std_logic_vector(31 downto 0);
...
begin
...
index := to_integer(addr(5 downto 4));
word := to_integer(addr(3 downto 2));
cblock := cache(index); -- has valid (154), tag (153 downto 128)
-- W0 (127 downto 96), W1(95 downto 64)
-- W2(63 downto 32), W3 (31 downto 0)
-- cblock is the shaded block in handout
...
quad_word_address := to_integer(addr(13 downto 4));
W0 := memory(quad_word_address*4+0);
W1 := memory(quad_word_address*4+1); -- ...
-- fill in cblock with new words, then
cache(index) <= cblock after 30 ns; -- 3 clock delay
miss <= '1', '0' after 30 ns; -- miss is '1' for 30 ns
...
-- the part3a.chk file has 'inst' set to zero while 'miss' is 1
-- not required but cleans up the "diff"
debug: process -- used to show cache
variable my_line : LINE; -- not part of working circuit
begin
wait for 9.5 ns; -- just before rising clock
for I in 0 to 3 loop
write(my_line, string'("line="));
write(my_line, I);
write(my_line, string'(" V="));
write(my_line, cache_ram(I)(154));
write(my_line, string'(" tag="));
hwrite(my_line, cache_ram(I)(151 downto 128)); -- ignore top bit
write(my_line, string'(" w0="));
hwrite(my_line, cache_ram(I)(127 downto 96));
write(my_line, string'(" w1="));
hwrite(my_line, cache_ram(I)(95 downto 64));
write(my_line, string'(" w2="));
hwrite(my_line, cache_ram(I)(63 downto 32));
write(my_line, string'(" w3="));
hwrite(my_line, cache_ram(I)(31 downto 0));
writeline(output, my_line);
end loop;
writeline(output, my_line); -- blank line
wait for 0.5 ns; -- rest of clock
end process debug;
end architecture behavior; -- of cache_memory
For debugging your cache, you might find it convenient to add
this 'debug' print process inside the instruction_memory architecture:
Then diff -iw part3a.out part3a_print.chk
debug: process -- used to print contents of I cache
variable my_line : LINE; -- not part of working circuit
begin
wait for 9.5 ns; -- just before rising clock
for I in 0 to 3 loop
write(my_line, string'("line="));
write(my_line, I);
write(my_line, string'(" V="));
write(my_line, cache(I)(154));
write(my_line, string'(" tag="));
hwrite(my_line, cache(I)(151 downto 128)); -- ignore top bits
write(my_line, string'(" w0="));
hwrite(my_line, cache(I)(127 downto 96));
write(my_line, string'(" w1="));
hwrite(my_line, cache(I)(95 downto 64));
write(my_line, string'(" w2="));
hwrite(my_line, cache(I)(63 downto 32));
write(my_line, string'(" w3="));
hwrite(my_line, cache(I)(31 downto 0));
writeline(output, my_line);
end loop;
wait for 0.5 ns; -- rest of clock
end process debug;
see part3a_print.chk with debug
You may print out signals such as 'miss' using prtmiss from.
debug.txt
Change MEMread : std_logic := '1'; to
MEMread : std_logic := '0'; for part3b.
You submit on GL using: submit cs411 part3 part3a.vhdl
Do a write through cache for the data memory.
(It must work to the point that results in main memory are
correct at the end of the run and the timing is correct,
partial credit for partial functionality)
You submit this as part3b.vhdl
Cache hierarchy on a multiple core CPU.
AMD quad core to six core to shared memory.
17.6 GBs front side bus, DDR-800 RAM
Possible behavioral, not required, VHDL to set up the start of a cache:
(no partial credit for just putting this in your cache.)
-- add in or out signals to entity instruction_memory as needed
-- for example, 'clk' 'clear' 'miss'
architecture behavior of instruction_memory is
subtype block_type is std_logic_vector(154 downto 0);
type cache_type is array (0 to 3) of block_type;
signal cache : cache_type := (others=>(others=>'0'));
-- now we have a cache memory initialized to zero
begin -- behavior
inst_mem:
process ... -- whatever, does not have to be just 'addr'
variable quad_word_address : natural; -- for memory fetch
variable cblock : block_type;-- the shaded block in the cache
variable index : natural; -- index into cache to get a block
variable word : natural; -- select a word
variable my_line : line; -- for debug printout
variable W0 : std_logic_vector(31 downto 0);
...
begin
...
index := to_integer(addr(5 downto 4));
word := to_integer(addr(3 downto 2));
cblock := cache(index); -- has valid (154), tag (153 downto 128)
-- W0 (127 downto 96), W1(95 downto 64)
-- W2(63 downto 32), W3 (31 downto 0)
-- cblock is the shaded block in handout
...
quad_word_address := to_integer(addr(13 downto 4));
W0 := memory(quad_word_address*4+0);
W1 := memory(quad_word_address*4+1); -- ...
-- fill in cblock with new words, then
cache(index) <= cblock after 30 ns; -- 3 clock delay
miss <= '1', '0' after 30 ns; -- miss is '1' for 30 ns
...
-- the part3a.chk file has 'inst' set to zero while 'miss' is 1
-- not required but cleans up the "diff"
debug: process -- used to show cache
variable my_line : LINE; -- not part of working circuit
begin
wait for 9.5 ns; -- just before rising clock
for I in 0 to 3 loop
write(my_line, string'("line="));
write(my_line, I);
write(my_line, string'(" V="));
write(my_line, cache_ram(I)(154));
write(my_line, string'(" tag="));
hwrite(my_line, cache_ram(I)(151 downto 128)); -- ignore top bit
write(my_line, string'(" w0="));
hwrite(my_line, cache_ram(I)(127 downto 96));
write(my_line, string'(" w1="));
hwrite(my_line, cache_ram(I)(95 downto 64));
write(my_line, string'(" w2="));
hwrite(my_line, cache_ram(I)(63 downto 32));
write(my_line, string'(" w3="));
hwrite(my_line, cache_ram(I)(31 downto 0));
writeline(output, my_line);
end loop;
writeline(output, my_line); -- blank line
wait for 0.5 ns; -- rest of clock
end process debug;
end architecture behavior; -- of cache_memory
For debugging your cache, you might find it convenient to add
this 'debug' print process inside the instruction_memory architecture:
Then diff -iw part3a.out part3a_print.chk
debug: process -- used to print contents of I cache
variable my_line : LINE; -- not part of working circuit
begin
wait for 9.5 ns; -- just before rising clock
for I in 0 to 3 loop
write(my_line, string'("line="));
write(my_line, I);
write(my_line, string'(" V="));
write(my_line, cache(I)(154));
write(my_line, string'(" tag="));
hwrite(my_line, cache(I)(151 downto 128)); -- ignore top bits
write(my_line, string'(" w0="));
hwrite(my_line, cache(I)(127 downto 96));
write(my_line, string'(" w1="));
hwrite(my_line, cache(I)(95 downto 64));
write(my_line, string'(" w2="));
hwrite(my_line, cache(I)(63 downto 32));
write(my_line, string'(" w3="));
hwrite(my_line, cache(I)(31 downto 0));
writeline(output, my_line);
end loop;
wait for 0.5 ns; -- rest of clock
end process debug;
see part3a_print.chk with debug
You may print out signals such as 'miss' using prtmiss from.
debug.txt
Change MEMread : std_logic := '1'; to
MEMread : std_logic := '0'; for part3b.
You submit on GL using: submit cs411 part3 part3a.vhdl
Do a write through cache for the data memory.
(It must work to the point that results in main memory are
correct at the end of the run and the timing is correct,
partial credit for partial functionality)
You submit this as part3b.vhdl
Cache hierarchy on a multiple core CPU.
AMD quad core to six core to shared memory.
17.6 GBs front side bus, DDR-800 RAM

 part3b
part3b
<- previous index next ->