Release 8.1.5
A67792-01
Library |
Product |
Contents |
Index |
| Oracle8i Utilities Release 8.1.5 A67792-01 |
|
![]()
![]()
This chapter explains the basic concepts of loading data into an Oracle database with SQL*Loader. This chapter covers the following topics:
SQL*Loader loads data from external files into tables of an Oracle database.
SQL*Loader:
Figure 3-1, "SQL*Loader Overview" shows the basic components of a SQL*Loader session.
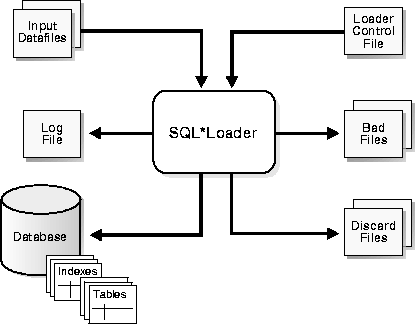
SQL*Loader takes as input a control file, which controls the behavior of SQL*Loader, and one or more datafiles. Output of the SQL*Loader is an Oracle database (where the data is loaded), a log file, a bad file, and potentially a discard file.
The control file is a text file written in a language that SQL*Loader understands. The control file describes the task that the SQL*Loader is to carry out. The control file tells SQL*Loader where to find the data, how to parse and interpret the data, where to insert the data, and more. See Chapter 4, "SQL*Loader Case Studies" for example control files.
Although not precisely defined, a control file can be said to have three sections:
Some control file syntax considerations to keep in mind are:
See also Chapter 5, "SQL*Loader Control File Reference" for details about control file syntax and its semantics.
The other input to SQL*Loader, other than the control file, is the data. SQL*Loader reads data from one or more files (or operating system equivalents of files) specified in the control file. See INFILE: Specifying Datafiles. From SQL*Loader's perspective, the data in the datafile is organized as records. A particular datafile can be in fixed record format, variable record format, or stream record format.
Important: If data is specified inside the control file (that is, INFILE * was specified in the control file), then tthe data is interpreted in the stream record format with the default record terminator.
When all the records in a datafile are of the same byte length, the file is in fixed record format. Although this format is the least flexible, it does result in better performance than variable or stream format. Fixed format is also simple to specify, for example:
INFILE <datafile_name> "fix n"
specifies that SQL*Loader should interpret the particular datafile as being in fixed record format where every record is n bytes long.
Example 3-1 shows a control file that specifies a datafile that should be interpreted in the fixed record format. The datafile in the example contains five physical records. The first physical record is [001, od, ] which is exactly eleven bytes (assuming a single-byte character set). The second record is [0002,fghi,] followed by the newline character which is the eleventh byte, etc.
load data infile 'example.dat' "fix 11" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: 001, cd, 0002,fghi, 00003,lmn, 1, "pqrs", 0005,uvwx,
When you specify that a datafile is in variable record format, SQL*Loader expects to find the length of each record in a character field at the beginning of each record in the datafile. This format provides some added flexibility over the fixed record format and a performance advantage over the stream record format. For example, you can specify a datafile which is to be interpreted as being in variable record format as follows:
INFILE "datafile_name" "var n"
where n specifies the number of bytes in the record length field. Note that if n is not specified, it defaults to five. If it is not specified, SQL*Loader assumes a length of five. Also note that specifying n larger than 2^32 -1 will result in an error.
Example 3-2 shows a control file specification that tells SQL*Loader to look for data in the datafile example.dat and to expect variable record format where the record length fields are 3 bytes long. The example.dat datafile consists of three physical records, first specified to be 009 (i.e. 9) bytes long, the second 010 bytes long and the third 012 bytes long. This example also assumes a single-byte character set for the datafile.
load data infile 'example.dat' "var 3" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: 009hello,cd,010world,im, 012my,name is,
Stream record format is the most flexible format. There is, however, some performance impact. In stream record format, records are not specified by size, rather SQL*Loader forms records by scanning for the record terminator.
The specification of a datafile to be interpreted as being in stream record format looks like:
INFILE <datafile_name> ["str 'terminator_string'"]
where the 'terminator_string' is a string specified using alpha-numeric characters. However, in the following cases the terminator_string should be specified as a hexadecimal string (which, if character encoded in the character set of the datafile, would form the desired terminator_string):
If no terminator_string is specified, it defaults to the newline (end-of-line) character(s) (line-feed in Unix-based platforms, carriage return followed by a line-feed on Microsoft platforms, etc.).
Example 3-3 illustrates loading in stream record format where the terminator string is specified using a hex-string. The string X'7c0a', assuming an ASCII character set, translates to '|' followed by the newline character '\n'. The datafile in the example, consists of two records, both properly terminated by the '|\n' string (i.e. X'7c0a').
load data infile 'example.dat' "str X'7c0a'" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: hello,world,| james,bond,|
SQL*Loader organizes the input data into physical records, according to the specified record format. By default a physical record is a logical record, but for added flexibility, SQL*Loader can be instructed to combine a number of physical records into a logical record.
SQL*Loader can be instructed to follow one of the following two logical record forming strategies:
Case 4: Loading Combined Physical Records demonstrates using continuation fields to form one logical record from multiple physical records.
For more information see Assembling Logical Records from Physical Records
Once a logical record is formed, field setting on the logical record is done. Field setting is the process where SQL*Loader, based on the control file field specifications, determines what part of the data in the logical record corresponds to which field in the control file. Note that it is possible for two or more field specifications to claim the same data; furthermore, a logical record can contain data which is claimed by no control file field specification.
Most control file field specifications claim a particular part of the logical record. This mapping takes the following forms:
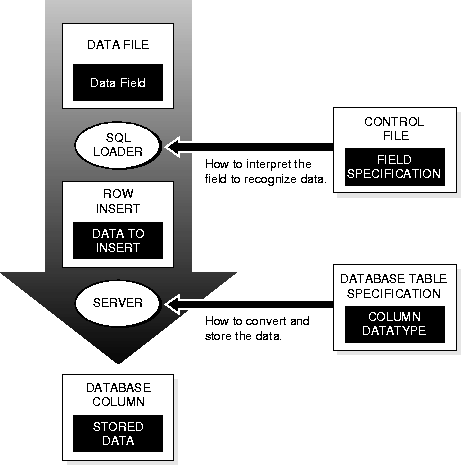
Figure 3-2 shows the stages in which datafields in the datafile are converted into columns in the database during a conventional path load (direct path loads are conceptually similar, but the implementation is different.) The top of the diagram shows a data record containing one or more datafields. The bottom shows the destination database column. It is important to understand the intervening steps when using SQL*Loader.
Figure 3-2 depicts the "division of labor" between SQL*Loader and the Oracle server. The field specifications tell SQL*Loader how to interpret the format of the datafile. The Oracle server then converts that data and inserts it into the database columns, using the column datatypes as a guide. Keep in mind the distinction between a field in a datafile and a column in the database. Remember also that the field datatypes defined in a SQL*Loader control file are not the same as the column datatypes.
SQL*Loader uses the field specifications in the control file to parse the input data and populate the bind arrays which correspond to a SQL insert statement using that data. The insert statement is then executed by the Oracle server to be stored in the table. The Oracle server uses the datatype of the column to convert the data into its final, stored form. There are two conversion steps:
In Figure 3-3, two CHAR fields are defined for a data record. The field specifications are contained in the control file. Note that the control file CHAR specification is not the same as the database CHAR specification. A data field defined as CHAR in the control file merely tells SQL*Loader how to create the row insert. The data could then be inserted into a CHAR, VARCHAR2, NCHAR, NVARCHAR, or even a NUMBER column in the database, with the Oracle8i server handling any necessary conversions.
By default, SQL*Loader removes trailing spaces from CHAR data before passing it to the database. So, in Figure 3-3, both field A and field B are passed to the database as three-column fields. When the data is inserted into the table, however, there is a difference.
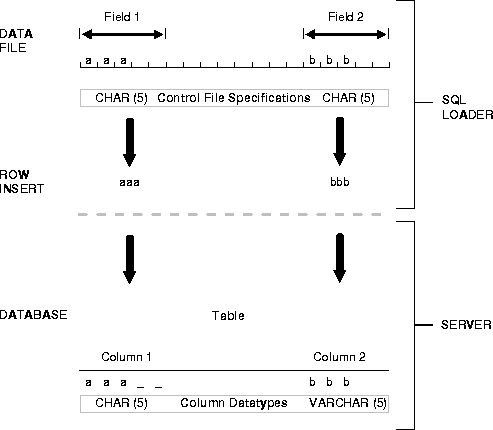
Column A is defined in the database as a fixed-length CHAR column of length 5. So the data (aaa) is left justified in that column, which remains five characters wide. The extra space on the right is padded with blanks. Column B, however, is defined as a varying length field with a maximum length of five characters. The data for that column (bbb) is left-justified as well, but the length remains three characters.
The name of the field tells SQL*Loader what column to insert the data into. Because the first data field has been specified with the name "A" in the control file, SQL*Loader knows to insert the data into column A of the target database table.
It is useful to keep the following points in mind:
Records read from the input file might not be inserted into the database. Figure 3-4 shows the stages at which records may be rejected or discarded.
The bad file contains records rejected, either by SQL*Loader or by Oracle. Some of the possible reasons for rejection are discussed in the next sections.
Records are rejected by SQL*Loader when the input format is invalid. For example, if the second enclosure delimiter is missing, or if a delimited field exceeds its maximum length, SQL*Loader rejects the record. Rejected records are placed in the bad file. For details on how to specify the bad file, see BADFILE: Specifying the Bad File.
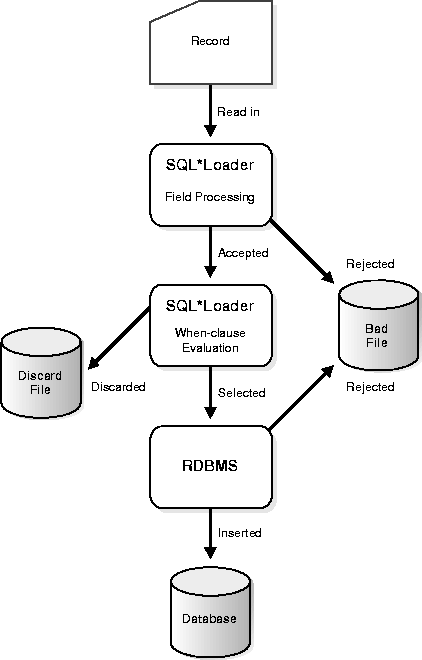
After a record is accepted for processing by SQL*Loader, a row is sent to Oracle for insertion. If Oracle determines that the row is valid, then the row is inserted into the database. If not, the record is rejected, and SQL*Loader puts it in the bad file. The row may be rejected, for example, because a key is not unique, because a required field is null, or because the field contains invalid data for the Oracle datatype.
The bad file is written in the same format as the datafile. So rejected data can be loaded with the existing control file after necessary corrections are made.
Case 4: Loading Combined Physical Records is an example of the use of a bad file.
As SQL*Loader executes, it may create a file called the discard file. This file is created only when it is needed, and only if you have specified that a discard file should be enabled (see Specifying the Discard File). The discard file contains records that were filtered out of the load because they did not match any record-selection criteria specified in the control file.
The discard file therefore contains records that were not inserted into any table in the database. You can specify the maximum number of such records that the discard file can accept. Data written to any database table is not written to the discard file.
The discard file is written in the same format as the datafile. The discard data can be loaded with the existing control file, after any necessary editing or correcting.
Case 4: Loading Combined Physical Records shows how the discard file is used. For more details, see Specifying the Discard File.
When SQL*Loader begins execution, it creates a log file. If it cannot create a log file, execution terminates. The log file contains a detailed summary of the load, including a description of any errors that occurred during the load. For details on the information contained in the log file, see Chapter 7, "SQL*Loader: Log File Reference". All of the case studies in Chapter 4 also contain sample log files.
SQL*Loader provides two methods to load data: Conventional Path, which uses a a SQL INSERT statement with a bind array, and Direct Path, which loads data directly into a database. These modes are discussed below and, more thoroughly, in Chapter 8, "SQL*Loader: Conventional and Direct Path Loads". The tables to be loaded must already exist in the database, SQL*Loader never creates tables, it loads existing tables. Tables may already contain data, or they may be empty.
The following privileges are required for a load:
Additional Information: For Trusted Oracle, in addition to the above privileges, you must also have write access to all labels you are loading data into in the Trusted Oracle database. See your Trusted Oracle documentation."
During conventional path loads, the input records are parsed according to the field specifications, and each data field is copied to its corresponding bind array. When the bind array is full (or there is no more data left to read), an array insert is executed. For more information on conventional path loads, see Data Loading Methods. For information on the bind array, see Determining the Size of the Bind Array.
Note that SQL*Loader stores LOB fields after a bind array insert is done. Thus, if there are any errors in processing the LOB field (for example, the LOBFILE could not be found), the LOB field is left empty.
There are no special requirements for tables being loaded via the conventional path.
A direct path load parses the input records according to the field specifications, converts the input field data to the column datatype and builds a column array. The column array is passed to a block formatter which creates data blocks in Oracle database block format. The newly formatted database blocks are written directly to the database bypassing most RDBMS processing. Direct path load is much faster than conventional path load, but entails several restrictions. For more information on the direct path, see Data Loading Methods.
Note: You cannot use direct path for LOBs, VARRAYs, objects, or nested tables.
A parallel direct path load allows multiple direct path load sessions to concurrently load the same data segments (allows intra-segment parallelism). Parallel Direct Path is more restrictive than Direct Path. For more information on the parallel direct path, see Data Loading Methods.
You can use SQL*Loader to bulk load objects, collections, and LOBs. It is assumed that you are familiar with the concept of objects and with Oracle's implementation of object support as described in Oracle8i Concepts, and the Oracle8i Administrator's Guide.
SQL*Loader supports loading of the following two object types:
When a column of a table is of some object type, the objects in that column are referred to as column-objects. Conceptually such objects are stored in entirety in a single column position in a row. These objects do not have object identifiers and cannot be referenced.
These objects are stored in tables, known as object tables, that have columns corresponding to the attributes of the object. The object tables have an additional system generated column, called SYS_NC_OID$, that stores system generated unique identifiers (OID) for each of the objects in the table. Columns in other table can refer to these objects by using the OIDs.
Please see Loading Column Objects and Loading Object Tables for details on using SQL*Loader control file data definition language to load these object types.
SQL*Loader supports loading of the following two collection types:
A nested table is a table that appears as a column in another table. All operations that can be performed on other tables can also be performed on nested tables.
VARRYs are variable sized arrays. An array is an ordered set of built-in types or objects, called elements. Each array element is of the same type and has an index which is a number corresponding to the element's position in the VARRAY.
When creating a VARRAY type, you must specify the maximum size. Once you have declared a varray type, it can be used as the datatype of a column of a relational table, as an object type attribute, or as a PL/SQL variable.
Please see Loading Collections (Nested Tables and VARRAYs) for details on using SQL*Loader control file data definition language to load these collection types.
A LOB is a large object type. This release of SQL*Loader supports loading of four LOBs types:
LOBs can be column datatypes, and with the exception of the NCLOB, they can be an object's attribute datatypes. LOBs can have an actual value, they can be NULL, or they can be "empty".
Please see Loading LOBs for details on using SQL*Loader control file data definition language to load these LOB types.
Note that, in order to provide object support the behavior of certain DDL clauses and certain restrictions are different than in previous releases. These changes apply in all cases, not just when you are loading objects, collections, or LOBs. For example:
In stream record format, the newline character marks the end of a physical record. Starting with release 8.1, you can specify a custom record separator in the OS-file-processing string. See New SQL*Loader DDL Support for Objects, Collections, and LOBs for more details.
The usual syntax of following the INFILE directive with the "var" string (see Oracle8i Concepts) has been extended to include the number of characters, at the beginning of each record, which are to be interpreted as the record length specifiers. See the syntax information in Chapter 5.
Note that the default, in the case that no value is specified, is 5 characters. Also note that the max size of a variable record is 2^32-1; specifying larger values will result in an error.
If the field_condition is true, the DEFAULTIF clause initializes the LOB/Collection to empty (not null).
If the field_condition is true, the NULLIF clause initializes the LOB/Collection to null as it does for other datatypes.
Note also that you can chain field_conditions arguments using the AND logical operator. See Chapter 5 for syntax details.
In previous version of SQL Loader, you could load fields which were delimited (terminated or enclosed) by a character. Beginning with this release, the delimiter can be one or more characters long. The syntax to specify delimited fields remains the same except that you can specify entire strings of characters as delimiters.
As with single character delimiters, when specifying string delimiters, one should take into consideration the character set of the datafile. When the character set of the datafile is different than that of the control file, you can specify the delimiters in hexadecimal (i.e. X'<hexadecimal string>'). If the delimiters are indeed specified in hex., the specification must consist of characters that are valid in the character set of the input datafile. On the other hand, if hexadecimal specification is not used, the delimiter specification is considered to be in the client's (i.e. control file's) character set. In this case, the delimiter is converted into the datafile's character set before searching for the delimiter in the datafile.
Note the following:
SQL Strings are not supported for LOBs, BFILEs, object columns, nested tables, or varrays, therefore, you cannot specify SQL Strings as part of a filler field specification.
To facilitate loading, you have available a new keyword, FILLER. You use this keyword to specify a filler field which is a datafile mapped field which does not correspond to a database column.
The filler field is assigned values from the datafield to which it is mapped. The filler field can be used as an argument to a number of functions, for example, NULLIF. See the specification for a function's syntax in SQL*Loader's Data Definition Language (DDL) Syntax Diagrams to see if a filler field can be used as an argument.
The syntax for a filler field is same as that for a column based field except that a filler field's name is followed by the keyword FILLER.
Filler fields can be used in field condition specifications in NULLIF, DEFAULTIF, and WHEN clauses. However, they cannot be used in SQL strings.
Filler field specifications cannot contain a NULLIF/DEFAULTIF clause. See Chapter 5, "SQL*Loader Control File Reference" for more detail on the filler field syntax.
Filler fields are initialized to NULL if the TRAILING NULLCOLS is specified and applicable. Note that if another field references a nullified filler field, an error is generated.
The following sections discuss new concepts specific to using SQL*Loader to load objects, collections, and LOBs.
The data to be loaded into some of the new datatypes, like LOBs and collections, can potentially be very lengthy; consequently, it is likely that you will want to have such data instances out of line from the rest of the data. LOBFILES and Secondary Data Files (SDFs) provide a method to separate lengthy data.
LOBFILES are relatively simple datafiles that facilitate LOB loading. The attribute that distinguishes LOBFILEs from the primary datafiles is that in LOBFILEs there is no concept of a record. In LOBFILEs the data is in any of the following type fields:
Note: The clause PRESERVE BLANKS is not applicable to fields read from a LOBFILE.
See Chapter 5 for LOBFILE syntax.
Note: A field read from a LOBFILE cannot be used as an argument to a clause (for example, the NULLIF clause).
Secondary-Data-File are files similar in concept to the primary datafiles. Like primary datafiles, SDFs are a collection of records and each record is made up of fields. The SDFs are specified on a per control-file-field basis.
You use the SDF keyword to specify SDFs. The SDF keyword can be followed by either the file specification string (see Specifying Filenames and Objects Names) or a filler field (see Secondary Data Files (SDFs) and LOBFILES) which is mapped to a datafield containing file specification string(s).
Note that as for a primary datafile, the following can be specified for each SDF:
See Chapter 5 for the SDF syntax.
Be aware that with SQL*Loader support for complex datatypes like column-objects, the possibility arises that two identical field names could exist in the control file, one corresponding to a column, the other corresponding to a column object's attribute. Certain clauses can refer to fields (for example, WHEN, NULLIF, DEFAULTIF, SID, OID, REF, BFILE, etc.) causing a naming conflict if identically named fields exist in the control file.
Therefore, if you use clauses that refer to fields, you must specify the full name (for example, if field fld1 is specified to be a COLUMN OBJECT and it contains field fld2, when specifying fld2 in a clause such as NULLIF, you must use the full field name fld1.fld2).
Say for example, you need to load employee names, employee ids, and employee resumes. You can read the employee names and ids from the main datafile(s), while you could read the resumes, which can be quite lengthy, from LOBFILEs.
You can specify SDFs and LOBFILEs either statically (you specify the actual name of the file) or dynamically (you use a filler field as the source of the filename). In either case, when the EOF of a SDF/LOBFILE is reached, the file is closed and further attempts at sourcing data from that particular file produce results equivalent to sourcing data from an empty field.
In the case of the dynamic secondary file specification this behavior is slightly different. Whenever the specification changes to reference a new file, the old file is closed and the data is read from the beginning of the newly referenced file.
Note that this dynamic switching of the datasource files has a resetting effect. For example, when switching from the current file to a previously opened file, the previously opened file is reopened, and the data is read from the beginning of the file.
You should not specify the same SDF/LOBFILE as the source of two different fields. If you do so, typically, the two fields will read the data independently.
The Oracle8i SQL*Loader supports loading partitioned objects in the database. A partitioned object in Oracle is a table or index consisting of partitions (pieces) that have been grouped, typically by common logical attributes. For example, sales data for the year 1997 might be partitioned by month. The data for each month is stored in a separate partition of the sales table. Each partition is stored in a separate segment of the database and can have different physical attributes.
Oracle8i SQL*Loader Partitioned Object Support enables SQL*Loader to load the following:
Oracle8i SQL*Loader supports partitioned objects in all three paths (modes):
Parallel direct path loads are used for intra-segment parallelism. Note that inter-segment parallelism can be achieved by concurrent single partition direct path loads with each load session loading a different partition of the same table.
Oracle provides a direct path load API for application developers. Please see the Oracle Call Interface Programmer's Guide for more information.