Release 8.1.5
A67784-01
Library |
Product |
Contents |
Index |
| Oracle8i Distributed Database Systems Release 8.1.5 A67784-01 |
|
![]()
![]()
This chapter describes the basic concepts and terminology of Oracle's distributed database architecture. The chapter includes:
For information about features new to the current Oracle8i Release, please see Getting to Know Oracle8i.
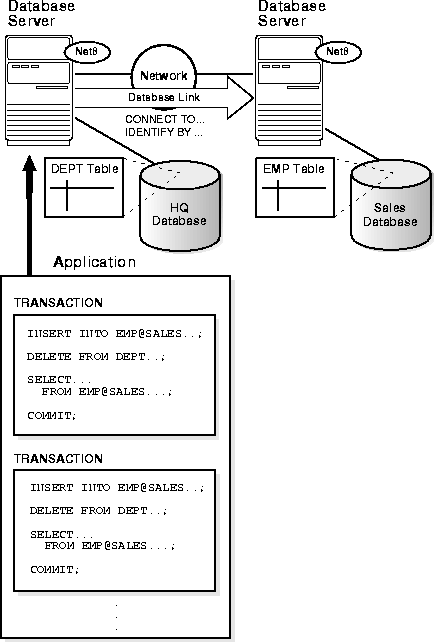
A distributed database is a set of databases stored on multiple computers that typically appears to applications as a single database. Consequently, an application can simultaneously access and modify the data in several databases in a network. Each Oracle database in the system is controlled by its local Oracle server but cooperates to maintain the consistency of the global distributed database. Figure 1-1 illustrates a representative Oracle distributed database system.
A database server is the Oracle software managing a database, and a client is an application that requests information from a server. Each computer in a system is a node. A node in a distributed database system act as a client, a server, or both, depending on the situation. For example, in Figure 1-1, the computer that manages the HQ database is acting as a database server when a statement is issued against its local data (for example, the second statement in each transaction issues a query against the local DEPT table), and is acting as a client when it issues a statement against remote data (for example, the first statement in each transaction is issued against the remote table EMP in the SALES database).
A client can connect directly or indirectly to a database server. In Figure 1-1, when the client application issues the first and third statements for each transaction, the client is connected directly to the intermediate HQ database and indirectly to the SALES database that contains the remote data.
To link the individual databases of a distributed database system, a network is necessary. The following sections explain more about network issues in an Oracle distributed database system.
All Oracle databases in a distributed database system use Oracle's networking software, Net8, to facilitate inter-database communication across a network. Just as Net8 connects clients and servers that operate on different computers of a network, it also allows database servers to communicate across networks to support remote and distributed transactions in a distributed database.
Net8 makes transparent the connectivity that is necessary to transmit SQL requests and receive data for applications that use the system. Net8 takes SQL statements from a client and packages them for transmission to an Oracle server over a supported industry-standard communication protocol or programmatic interfaces. Net8 also takes replies from a server and packages them for transmission back to the appropriate client. Net8 performs all processing independent of an underlying network operating system. For more information about Net8 and its features, see the Net8 Administrator's Guide.
Optionally, an Oracle network can use Oracle Names to provide the system with a global directory service. When an Oracle network supports a distributed database system, you can use Oracle Names servers as a central repositories of information about each database in the system to ease the configuration of distributed database access.
Each database in a distributed database is distinct from all other databases in the system and has its own global database name. Oracle forms a database's global database name by prefixing the database's network domain with the individual database's name. For example, Figure 1-2 illustrates a representative hierarchical arrangement of databases throughout a network.
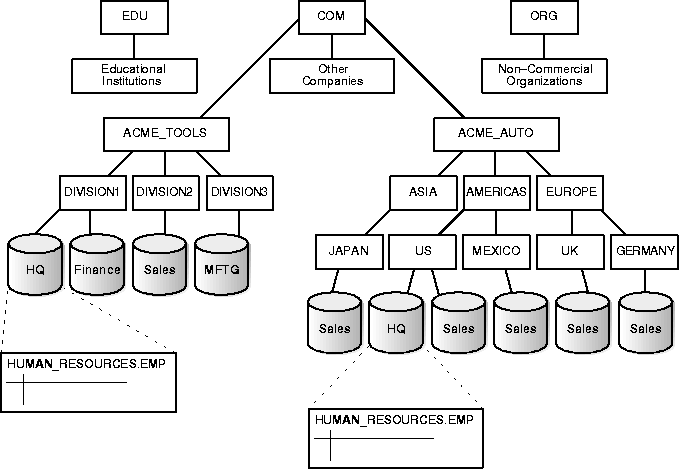
While several database's can have the same individual name, each database must have a unique global database name. For example, the network domains US.AMERICAS.ACME_AUTO.COM and UK.EUROPE.ACME_AUTO.COM each contain a SALES database.
SALES.US.AMERICAS.ACME_AUTO.COM SALES.UK.EUROPE.ACME_AUTO.COM
To facilitate application requests in a distributed database system, Oracle uses database links. A database link defines a one-way communication path from an Oracle database to another database.
Database links are essentially transparent to the users of an Oracle distributed database system, because the name of a database link is the same as the global name of the database to which the link points.
For example, the following SQL statement creates a database link in the local database that describes a path to the remote SALES.US.AMERICAS.ACME_AUTO.COM database.
CREATE DATABASE LINK sales.us.americas.acme_auto.com ... ;
After creating a database link, applications connected to the local database can access data in the remote SALES.US.AMERICAS.ACME_AUTO.COM database. The next section explains how applications can reference remote schema objects in a distributed database and includes examples of how SQL statements use database links.
|
Note: Oracle supports several different types of database links. For more information, see "Types of Database Links". |
To resolve application references to schema objects (a process called name resolution) Oracle forms object names using a hierarchical approach. For example, within a single database, Oracle guarantees that each schema has a unique name, and that within a schema, each object has a unique name. As a result, a schema object's name is always unique within the database. Furthermore, Oracle can easily resolve application references to an object's local name.
In a distributed database, a schema object such as a table is accessible to all applications in the system. Oracle simply extends the hierarchical naming model with global database names to effectively create global object names and resolve references to the schema objects in a distributed database system. For example, a query can reference a remote table by specifying its fully qualified name, including the database in which it resides.
SELECT * FROM scott.emp@sales.us.americas.acme_auto.com;
To complete the request, the local database server implicitly uses a database link that connects to the remote SALES database.
An Oracle distributed database system can incorporate Oracle databases of different versions. All supported releases of Oracle can participate in a distributed database system. However, the applications that work with the distributed database must understand the functionality that is available at each node in the system.
For example, a distributed database application cannot expect an Oracle7 database to understand the object SQL extensions that are available with Oracle8i.
The terms "distributed database" and "distributed processing" are closely related, but have very distinct meanings.
Oracle distributed database systems employ a distributed processing architecture to function. For example, an Oracle server acts as a client when it requests data that another Oracle server manages.
The terms "distributed database" and "database replication" are also closely related, yet different. In a pure distributed database, the system manages a single copy of all data and supporting database objects. Distributed database applications typically use distributed transactions to access both local and remote data and modify the global database in real-time.
Replication is the process of copying and maintaining database objects in multiple databases that make up a distributed database system. While replication relies on distributed database technology to function, database replication can offer applications benefits that are not possible within a pure distributed database environment.
Most commonly, replication is useful to improve the performance and protect the availability of applications because alternate data access options exist. For example, an application might normally access a local database rather than a remote server to minimize network traffic and achieve maximum performance. Furthermore, the application can continue to function if the local server experiences a failure, but other servers with replicated data remain accessible.
In an Oracle heterogeneous distributed database system at least one of the database systems is a non-Oracle system. To the application, the heterogeneous distributed database system appears as a single, local, Oracle database; the local Oracle server will be able to hide the distribution and heterogeneity of the data. The Oracle server accesses the non-Oracle system using Oracle8i Heterogeneous Services and a non-Oracle system-specific Heterogeneous Services Agent.
Heterogeneous Services is an integrated component within the Oracle8i server and the enabling technology for Oracle's next generation of Open Gateway products. Heterogeneous Services provides the common architecture and administration mechanisms for future Oracle gateway products and other heterogeneous access facilities, while providing upwardly compatible functionality for users of earlier Oracle Open Gateway releases.
See Chapter 5, "Understanding Oracle Heterogeneous Services" for more information.
For each non-Oracle system that you want to access, Heterogeneous Services requires an agent to access that particular non-Oracle system. The Heterogeneous Services agent communicates with the non-Oracle system, and with the Heterogeneous Services component in the Oracle server. On behalf of the Oracle server, the agent executes SQL, procedure, and transactional requests at the non-Oracle system.
A version 8 Gateway is the Oracle product name for a Heterogeneous Services agent that accesses a non-Oracle system procedurally or using SQL. However, Heterogeneous Services agents will also become available as products other than Oracle Transparent Gateways or Oracle Procedural Gateways. Throughout this guide we will use the more generic term Heterogeneous Services agents. If you purchased an Oracle Open Gateway version 8, you can substitute "Oracle Gateway version 8" for Heterogeneous Services Agent.
See your "Oracle Open Gateway Installation and User's Guide version 8.0" for detailed information on installation and configuration of version 8 gateways.
The features of the Heterogeneous Services include:
When you build applications on top of a distributed database system, there are several issues to consider. The following sections explain how applications access data in a distributed database.
Distributed query optimization is a default Oracle8i feature that reduces the amount of data transfer required between sites when you retrieve data from remote tables referenced in distributed SQL statements.
Distributed query optimization uses Oracle's cost-based optimizer to find or generate SQL expressions that extract only the necessary data from remote tables, process that data at a remote site, and send the results back to the local site for final processing. This reduces the amount of required data transfer, when compared to transferring all the table data to the local site for processing.
Using cost-based optimizer hints, such as DRIVING_SITE, NO_MERGE, and INDEX hints, you can further control where Oracle processes the data and how it accesses the data.
See "Tuning Distributed Queries" for more information.
A remote query is a query that selects information from one or more remote tables, all of which reside at the same remote node. For example:
SELECT * FROM scott.dept@sales.us.americas.acme_auto.com;
A remote update is an update that modifies data in one or more tables, all of which are located at the same remote node.
For example:
UPDATE scott.dept@sales.us.americas.acme_auto.com SET loc = 'NEW YORK' WHERE deptno = 10;
A distributed query retrieves information from two or more nodes. For example:
SELECT ename, dname FROM scott.emp e, scott.dept@sales.us.americas.acme_auto.com d WHERE e.deptno = d.deptno;
A distributed update modifies data on two or more nodes. A distributed update is possible using a PL/SQL subprogram unit, such as a procedure or trigger, that includes two or more remote updates that access data on different nodes. For example:
BEGIN UPDATE scott.dept@sales.us.americas.acme_auto.com SET loc = 'NEW YORK' WHERE deptno = 10; UPDATE scott.emp SET deptno = 11 WHERE deptno = 10; END;
Statements in the program are sent to the remote nodes, and the execution of it succeeds or fails as a unit.
Developers can code PL/SQL packages and procedures to support applications that work with a distributed database. Applications can make local procedure calls to perform work at the local database and remote procedure calls (RPCs) to perform work at a remote database. When a program calls a remote procedure, the local server passes all procedure parameters to the remote server in the call. For example:
BEGIN emp_mgmt.del_emp@sales.us.americas.acme_auto.com(1257); END;
When developing packages and procedures for distributed database systems, developers must code with an understanding of what program units should do at remote locations, and how to return the results to a calling application.
A remote transaction is a transaction that contains one or more remote statements, all of which reference the same remote node. For example:
UPDATE scott.dept@sales.us.americas.acme_auto.com SET loc = 'NEW YORK' WHERE deptno = 10; UPDATE scott.emp@sales.us.americas.acme_auto.com SET deptno = 11 WHERE deptno = 10; COMMIT;
A distributed transaction is a transaction that includes one or more statements that, individually or as a group, update data on two or more distinct nodes of a distributed database. For example:
UPDATE scott.dept@sales.us.americas.acme_auto.com SET loc = 'NEW YORK' WHERE deptno = 10; UPDATE scott.emp SET deptno = 11 WHERE deptno = 10; COMMIT;
A DBMS must guarantee that all statements in a transaction, distributed or non-distributed, either commit or rollback as a unit, so that if the transaction is designed properly, the data in the logical database is always consistent. The effects of an ongoing transaction should be invisible to all other transactions at all nodes; this should be true for transactions that include any type of operation, including queries, updates, or remote procedure calls.
The general mechanisms of transaction control in a non-distributed database are discussed in the Oracle8i Concepts. In a distributed database, Oracle must coordinate transaction control with the same characteristics over a network and maintain data consistency, even if a network or system failure occurs.
Oracle's two-phase commit mechanism guarantees that all database servers participating in a distributed transaction either all commit or all roll back the statements in the transaction. A two-phase commit mechanism also protects implicit DML operations performed by integrity constraints, remote procedure calls, and triggers.
|
Note: For more information about Oracle's two-phase commit mechanism, see Chapter 3, "Distributed Transactions". |
With minimal effort, you can make the functionality of an Oracle distributed database system transparent to users that work with the system. The goal of transparency is to make a distributed database system appear as though it is a single Oracle database. Consequently, the system does not burden developers and users of the system with complexities that would otherwise make distributed database application development challenging and detract from user productivity. The following sections explain more about transparency in a distributed database system.
An Oracle distributed database system has features that allow application developers and administrators to hide the physical location of database objects from applications and users. Location transparency exists when a user can universally refer to a database object such as a table, regardless of the node to which an application connects. Location transparency has several benefits, including:
Most typically, administrators and developers use synonyms to establish location transparency for the tables and supporting objects in an application schema. For example, the following statements create synonyms in a database for tables in another, remote database.
CREATE PUBLIC SYNONYM emp FOR scott.emp@sales.us.americas.acme_auto.com CREATE PUBLIC SYNONYM dept FOR scott.dept@sales.us.americas.acme_auto.com
Now, rather than access the remote tables with a query such as:
SELECT ename, dname FROM scott.emp@sales.us.americas.acme_auto.com e, scott.dept@sales.us.americas.acme_auto.com d WHERE e.deptno = d.deptno;
an application can issue a much simpler query that does not have to account for the location of the remote tables.
SELECT ename, dname FROM emp e, dept d WHERE e.deptno = d.deptno;
In addition to synonyms, developers can also use views and stored procedures to establish location transparency for applications that work in a distributed database system.
Oracle's distributed database architecture also provides query, update, and transaction transparency. For example, standard SQL commands such as SELECT, INSERT, UPDATE, and DELETE work just as they do in a non-distributed database environment. Additionally, applications control transactions using the standard SQL commands COMMIT, SAVEPOINT, and ROLLBACK--there is no requirement for complex programming or other special operations to provide distributed transaction control.
Each committed transaction has an associated system change number (SCN) to uniquely identify the changes made by the statements within that transaction. In a distributed database, the SCNs of communicating nodes are coordinated when:
Among other benefits, the coordination of SCNs among the nodes of a distributed database system allows global distributed read-consistency at both the statement and transaction level. If necessary, global distributed time-based recovery can also be completed.
Oracle also provide many features to transparently replicate data among the nodes of the system. For more information about Oracle's replication features, see Oracle8i Replication.
Just as there are unique issues to consider when developing applications for an Oracle distributed database system, there are special issues to understand for distributed database administration. The following sections explain the some special topics for managing databases in an Oracle distributed database system. See also Chapter 6, "Administering Oracle Heterogeneous Services"
Site autonomy means that each server participating in a distributed database is administered independently from all other databases, as though each database operates as a non-distributed database.
Although several databases can work together, each database is a distinct, separate repository of data that you manage individually. Some of the benefits of site autonomy in an Oracle distributed database include:
Although Oracle allows you to manage each database in a distributed database system independently, that is not to say that you should ignore the global requirements of the system.
For example, additional user accounts might be necessary in each database are necessary to support the links that you create to facilitate server-to-server connections. The following sections explain more about these particular topics and demonstrate the need for a global perspective of the entire distributed database environment when managing individual nodes in the system.
Oracle supports all of the security features that are available with a non-distributed database environment for distributed database systems, including:
The following sections explain some additional topics to consider when configuring an Oracle distributed database system.
In a distributed database system, you must carefully plan the user accounts and roles that are necessary to support applications using the system.
As you create the database links for the nodes in a distributed database system, determine what user accounts and roles each site needs to support server-to-server connections that use the links. See "Types of Database Links" for more information about the user accounts that must be available to support different types of database links in the system.
In a distributed environment, users typically require access to many network services. When it's necessary to configure separate authentications for each user to access each network service, security administration can become unwieldy, especially for large systems.
The use of a global authentication service is a common technique for simplifying security management for distributed environments.
In an Oracle client/server or distributed database environment, you have two options to support global authentication for users and roles:
The Net8 Advanced Networking Option also enables Net8 and related products to use network data encryption and checksumming so that data cannot be read or altered. It protects data from unauthorized viewing by using the RSA Data Security RC4 or the Data Encryption Standard (DES) encryption algorithm.
To ensure that data has not been modified, deleted, or replayed during transmission, the security services of the Advanced Networking Option can generate a cryptographically secure message digest and include it with each packet sent across the network.
For more information about these and other features of Net8's Advanced Networking Option, see the Net8 Administrator's Guide and Oracle Advanced Security Administrator's Guide.
The database administrator has several choices for tools to use when managing an Oracle distributed database system:
Enterprise Manager is Oracle's database administration tool. The graphical component of Enterprise Manager (Enterprise Manager/GUI) allows you to perform database administration tasks with the convenience of a graphical user interface (GUI).
The line mode component of Enterprise Manager provides a line-mode interface.
Enterprise Manager provides administrative functionality via an easy-to-use interface. You can use Enterprise Manager to:
Thus, you can re-execute statements without retyping them, a particularly useful feature if you need to execute lengthy statements repeatedly in a distributed database system.
Currently more than 60 companies produce more than 150 products that help manage Oracle databases and networks, providing a truly open environment.
Besides its network administration capabilities, Oracle Simple Network Management Protocol (SNMP) support allows an Oracle server to be located and queried by any SNMP-based network management system. SNMP is the accepted standard underlying many popular network management systems such as:
Additional Information: See the Oracle SNMP Support Reference Guide.
Oracle supports client/server environments where clients and servers use different character sets. The character set used by a client is defined by the value of the NLS_LANG parameter for the client session. The character set used by a server is its database character set. Data conversion is done automatically between these character sets if they are different. For more information about National Language Support features, refer to Oracle8i Reference.