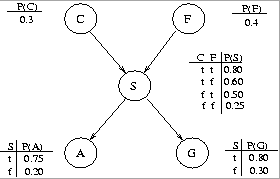
Using the chain rule, compute the probability P(~g, a, s, c, ~f).
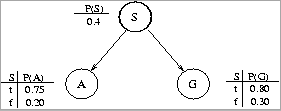
(a) (10 pts.) Compute P(A) in two ways:
(c) (5 pts.) The enterprising student notices that two types of people
drive SUVs: people from California (C) and people with large families (F).
After collecting some statistics, the student arrives at the following
form for the BN:
Using the chain rule, compute the probability P(~g, a, s, c, ~f).
(d) (6 pts.) Using the rules for determining when two variables are (conditionally) independent of each other in a BN, answer the following (T/F) for the BN given in (c):
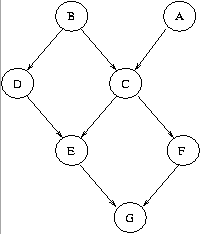
(a) (10 pts.) Suppose we have the query P(G) and the following elimination ordering: A, B, C, D, E, F. Show how the variable elimination algorithm would be applied to answer this query by listing, for each variable eliminated in sequence, the new factor generated, and the factors or probabilities that are used to generate this factor. The factors should be written in the form fv(X1, ..., Xk), where v is the variable eliminated at that step, and X1, ..., Xk are the variables on which this factor depends.
(b) (10 pts.) Elimination ordering affects the complexity of inference. Assume that all variables have the same domain size m > 2. Find an elimination ordering for the same query as in (a) whose time complexity, as a function of m, is worse than the ordering given above, and explain why this is the case. As in the above problem, show what factors are generated at each step.
| Outlook | Temp (F) | Humidity (%) | Windy? | Class |
| sunny | 75 | 70 | true | Play |
| sunny | 80 | 90 | true | Don't Play |
| sunny | 85 | 85 | false | Don't Play |
| sunny | 72 | 95 | false | Don't Play |
| sunny | 69 | 70 | false | Play |
| overcast | 72 | 90 | true | Play |
| overcast | 83 | 78 | false | Play |
| overcast | 64 | 65 | true | Play |
| overcast | 81 | 75 | false | Play |
| rain | 71 | 80 | true | Don't Play |
| rain | 65 | 70 | true | Don't Play |
| rain | 75 | 80 | false | Play |
| rain | 68 | 80 | false | Play |
| rain | 70 | 96 | false | Play |
(a) (10 pts.) At the root node for a decision tree in this domain, what are the information gains associated with the Outlook and Humidity attributes? (Use a threshold of 75 for humidity (i.e., assume a binary split: humidity <= 75 / humidity > 75.)
(b) (10 pts.) Again at the root node, what are the gain ratios associated with the Outlook and Humidity attributes (using the same threshold as in (a))?
(c) (5 pts.) Suppose you build a decision tree that splits on the Outlook
attribute at the root node. How many children nodes are there are at the
first level of the decision tree? Which branches require a further split
in order to create leaf nodes with instances belonging to a single class?
For each of these branches, which attribute can you split on to complete
the decision tree building process at the next level (i.e., so that at
level 2, there are only leaf nodes)? Draw the resulting decision tree,
showing the decisions (class predictions) at the leaves.
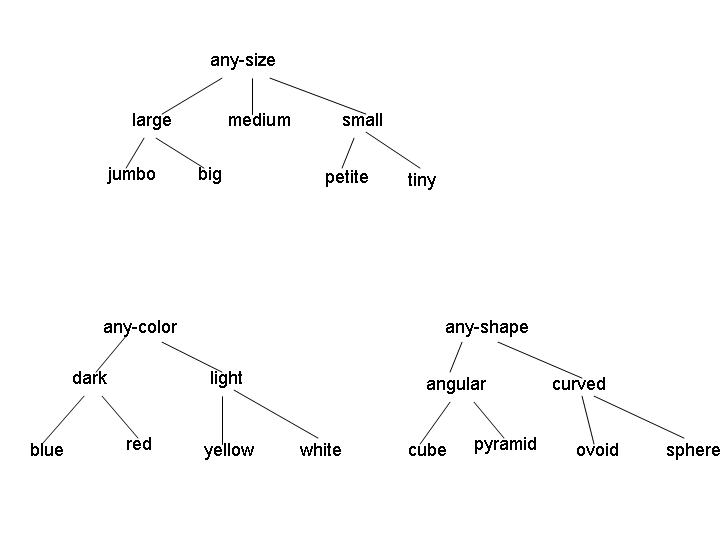
Examples of legal concepts in this domain include [medium light angular], [large red sphere], and [any-size any-color any-shape]. No disjunctive concepts are allowed, other than the implicit disjunctions represented by the internal nodes in the attribute hierarchies. (For example, the concept [large [red v yellow] curved] isn't allowed.)
(a) (5 points) Consider the initial version space for learning in this domain. What is the G set? How many elements are in the S set? Give one representative member of the initial S set.
(b) (5 points) Suppose the first instance I1 is a positive example, with attribute values [jumbo yellow ovoid]. After processing this instance, what are the G and S sets?
(c) (5 points) Now suppose the learning algorithm receives instance I2, a negative example, with attribute values [jumbo red pyramid]. What are the G and S sets after processing this example?
(d) (16 points - 4 points each) For this question, you should start with the version space that remains after I1 and I2 are processed. For each of the following combinations of instance type and events, give a single instance of the specified type that would cause the indicated event, if such an instance exists. If no such instance exists, explain why.
Bonus: (e) (5 points) If learning ends after I1 and I2 are
processed, how many concepts remain in the version space?